
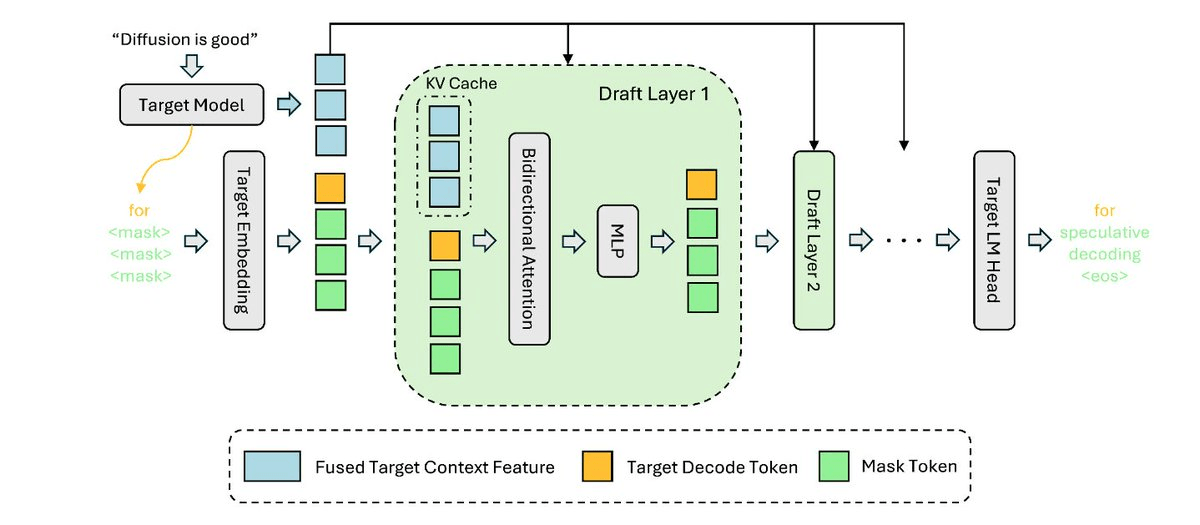
Speculative decoding has been one of the most impactful inference tricks of the past two years: use a small, cheap draft model to guess several tokens ahead, then let the big target model verify them all in one shot. The catch is that most draft models, including the popular EAGLE series, still generate those guesses one token at a time. That sequential bottleneck caps how fast you can go. DFlash, developed by Z Lab and now integrated into SGLang with Modal's help, breaks that ceiling.
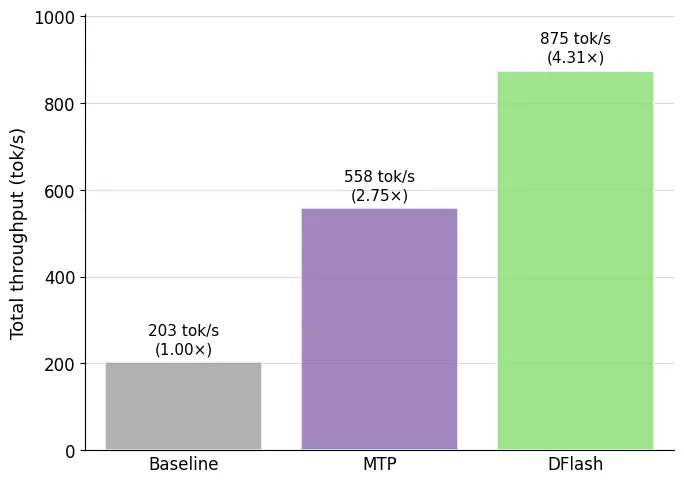
Using Modal and Z Lab's DFlash speculative decoding models with SGLang's newly default Spec V2 engine, you can achieve state-of-the-art latencies for LLM inference serving. The headline number: the jointly-released DFlash model for Qwen 3.5 397B-A17B achieves higher throughput than both the baseline model and native MTP speculation in all the settings benchmarked, hitting over 4.3x the throughput of baseline and 1.5x the throughput of MTP at concurrency 1 on the HumanEval coding dataset on 8xB200 GPUs.
The draft model bottleneck nobody talks about
GPUs offer massive compute, yet much of that power sits idle because autoregressive generation is inherently sequential: each token requires a full forward pass, reloading weights, and synchronizing memory at every step. Speculative decoding was supposed to fix this, but it only moved the problem. EAGLE is the state-of-the-art method for speculative decoding in LLM inference, but its autoregressive drafting creates a hidden bottleneck: the more tokens you speculate, the more sequential forward passes the drafter needs.
The same problem applies to native multi-token prediction (MTP) modules baked into models like DeepSeek-V4 and Gemma 4. Many speculative decoding methods still rely on sequential autoregression, but in the draft model instead of the target. The draft model generates draft tokens one-by-one, a poor fit for modern hardware and a limit on achievable speedup.
Two ideas that change the math
DFlash combines two distinct innovations that each independently improve performance, and compound when used together.
Block diffusion drafting. Z Lab developed DFlash, which uses a lightweight block diffusion draft model to generate an entire block of draft tokens in parallel, just the way GPUs and TPUs like. Block diffusion (a term borrowed from diffusion language models) means the draft model fills in a whole sequence of masked token positions simultaneously in a single forward pass, rather than left-to-right one at a time. With DFlash, K tokens cost the same as 1 token in the draft phase, so higher K values are more efficient with DFlash than with EAGLE-3.


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves