
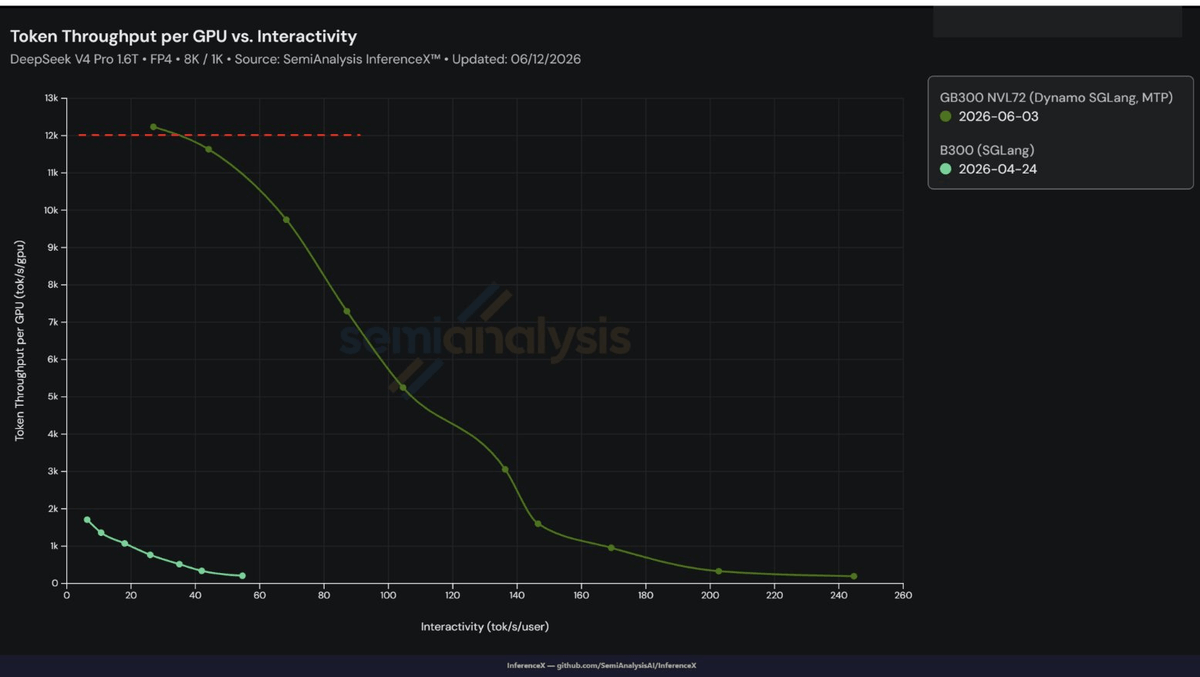
SGLang just hit a new inference record: over 12,000 output tokens per second per GPU on DeepSeek V4 Pro, the 1.6 trillion parameter MoE model, running on NVIDIA's GB300 NVL72 rack. The result was validated by SemiAnalysis's InferenceX benchmark suite and combines three separate performance levers: the GB300's Blackwell Ultra hardware, NVIDIA Dynamo for disaggregated serving, and Multi-Token Prediction (MTP) speculative decoding. It's a meaningful milestone, and the story behind it is more interesting than the headline number.
The Model, the Machine, and the Stack
DeepSeek V4 Pro is a 1.6 trillion total parameter MoE model with roughly 49 billion active parameters per token, a 1 million token context window, and MIT licensing. Despite the astronomical parameter count, only a fraction of the model activates per token, which is what makes MoE models uniquely suited to large-scale, high-throughput inference. V4 Pro features a hybrid attention design that combines Compressed Sparse Attention (CSA) with a new Heavily Compressed Attention (HCA) head for cheap long-context prefill.
The hardware underneath this benchmark is NVIDIA's GB300 NVL72, the current top of the Blackwell Ultra lineup. The GB300 NVL72 is the most powerful platform for LLM inference in the Blackwell family. What makes it especially well-suited for MoE models is the rack-scale NVLink domain: 72 GPUs are connected into a single high-bandwidth fabric, which keeps the all-to-all communication that MoE expert dispatch requires entirely on fast NVLink rather than spilling onto slower InfiniBand.
Three Levers, One Record
The 12K tokens/GPU/second figure is not the result of a single trick. It stacks three distinct optimizations on top of each other:
- NVFP4 quantization. Running MoE expert weights in FP4 precision reduces memory bandwidth pressure, halves the communication traffic for token dispatch, and taps into the GB300's 1.5x higher FP4 Tensor Core throughput compared to the previous Blackwell generation. It also frees HBM capacity for a larger KV cache, enabling higher concurrency.
- NVIDIA Dynamo for disaggregated inference. Dynamo is the orchestration layer above inference engines; it doesn't replace SGLang, it turns it into a coordinated multi-node inference system. Dynamo allows for disaggregated serving, which splits the prefill and decode stages of inferencing among multiple GPUs to optimize resource utilization and drive down the cost of tokens. In practice, SGLang's integration with Dynamo couples its KV-aware router with SGLang's own radix tree cache, enabling flexible KV cache transfer between prefill and decode workers.


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves