
Training an agent with reinforcement learning sounds straightforward until you realize the model is not generating one long sequence -- it is making dozens of separate calls to an inference engine, interleaved with tool outputs, harness messages, and retries. Every time you stitch those turns back together for the trainer, you are one subtle bug away from feeding it tokens the model never actually saw. LMSYS's new blog post on their Miles framework tears this problem open and shows exactly how they solved it.
The silent killer in agentic RL
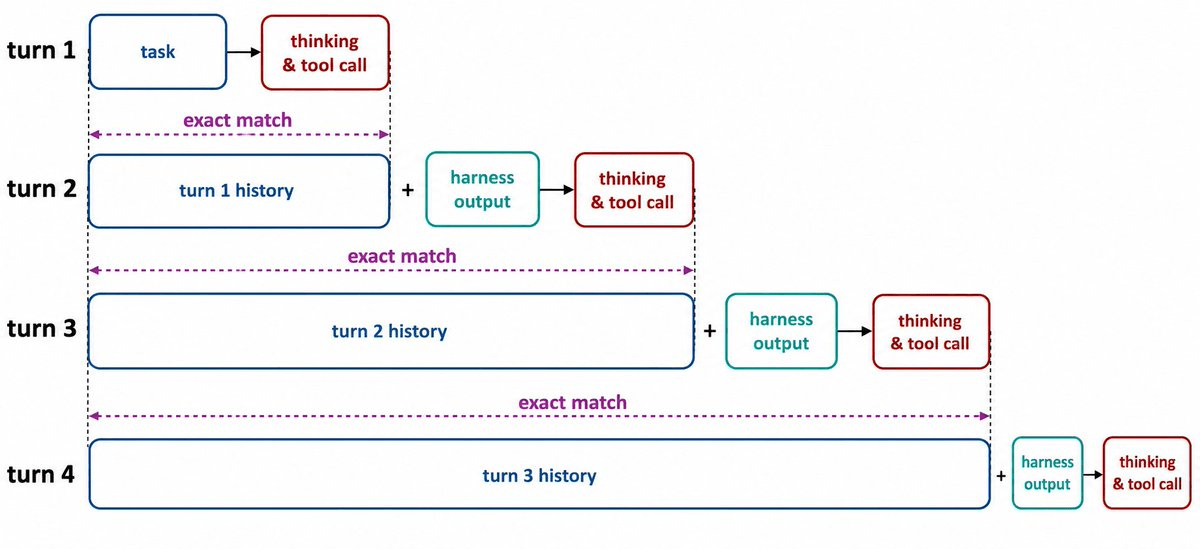
In standard single-turn RL, the trainer evaluates the same token sequence the model generated. Simple. But in agentic settings, a rollout is not a single generation -- it is a chain of model calls, tool outputs, harness messages, and resumed generations. The trainer needs to evaluate the entire trajectory as one contiguous sequence, but that sequence was built across many separate inference calls.
The Token-In-Token-Out (TITO) principle is the invariant that keeps this honest. TITO is a design principle that addresses one critical source of training-inference mismatch: whether the trainer evaluates the exact same token sequence that the inference engine consumed and produced during rollout. Violating it means the trainer is grading tokens based on a context the model never actually saw -- and the model silently drifts off-policy.
Why it costs you 10x compute to ignore this
There are two ways to package a multi-turn trajectory for the RL trainer:
- One sample per turn: Each turn is an independent training sample. Simple, but expensive.
- One sample per task: All turns are glued into one contiguous sequence. Efficient, but only safe if TITO holds.
For a typical SWE-Bench-like task, a trajectory consists of 30-50 turns, which means that to ingest the same amount of information, the one-sample-per-task option only has to spend an order of magnitude less compute compared with the per-turn option. That 10x compute reduction is only achievable if every token in the packed sequence is exactly what the model produced -- otherwise you are training on fabricated context.
The mathematical stakes are just as high. For a training sample to be on-policy, every sampled token should be evaluated by the trainer under the same conditional distribution that produced it during rollout. In transformers, that conditional distribution is entirely dependent on the preceding context of the token. Even a single mismatched token early in the sequence shifts the conditional probability for every token that follows it.


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves