
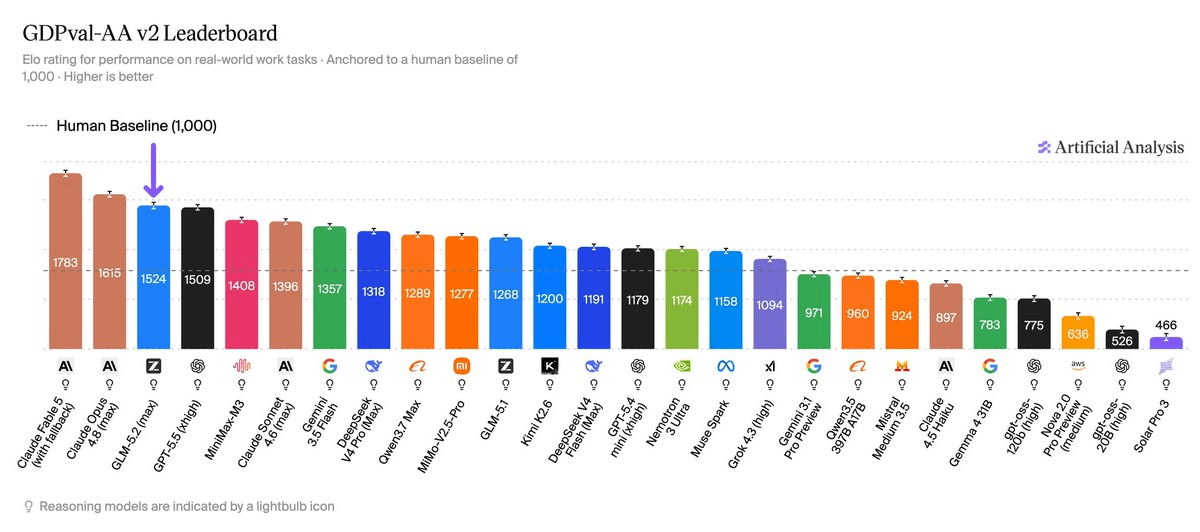
Artificial Analysis just published independent benchmark results for GLM-5.2, Z.ai's latest open-weights model, and the numbers are striking. On GDPval-AA, Artificial Analysis's primary measure of real-world agentic performance, GLM-5.2 scores 1524 Elo, placing it ahead of every other open-weights model and effectively level with OpenAI's GPT-5.5. That result, from an independently run evaluation rather than a vendor self-report, is what makes this worth paying attention to.
What GDPval-AA actually tests
Most benchmarks ask models to answer multiple-choice questions or fix isolated code bugs. GDPval-AA v2 evaluates complete deliverables: models operate in an agentic environment with tools, produce file outputs, and have their submissions scored through pairwise grading on relative quality. It tests AI models on real-world tasks across 44 occupations and 9 major industries, with models given shell access and web browsing capabilities in an agentic loop to solve tasks, with Elo ratings derived from blind pairwise comparisons.
The v2 upgrade Artificial Analysis is running now is meaningfully stricter than the original. It incorporates an upgraded sandbox with new and expanded dependencies, Elo scores re-baselined to human expert performance at 1000, a panel of three frontier LLM judges from leading labs replacing a single judge, and turn limits expanded to 250 turns to allow for even longer-horizon agent trajectories. In the evaluation thread, Artificial Analysis showed GLM-5.2 completing tasks like drafting a daily task list for a retail supervisor, drawing an IEC emergency-stop circuit schematic, and building a moodboard for an orchestral music video, all rendered exactly as produced.


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves