
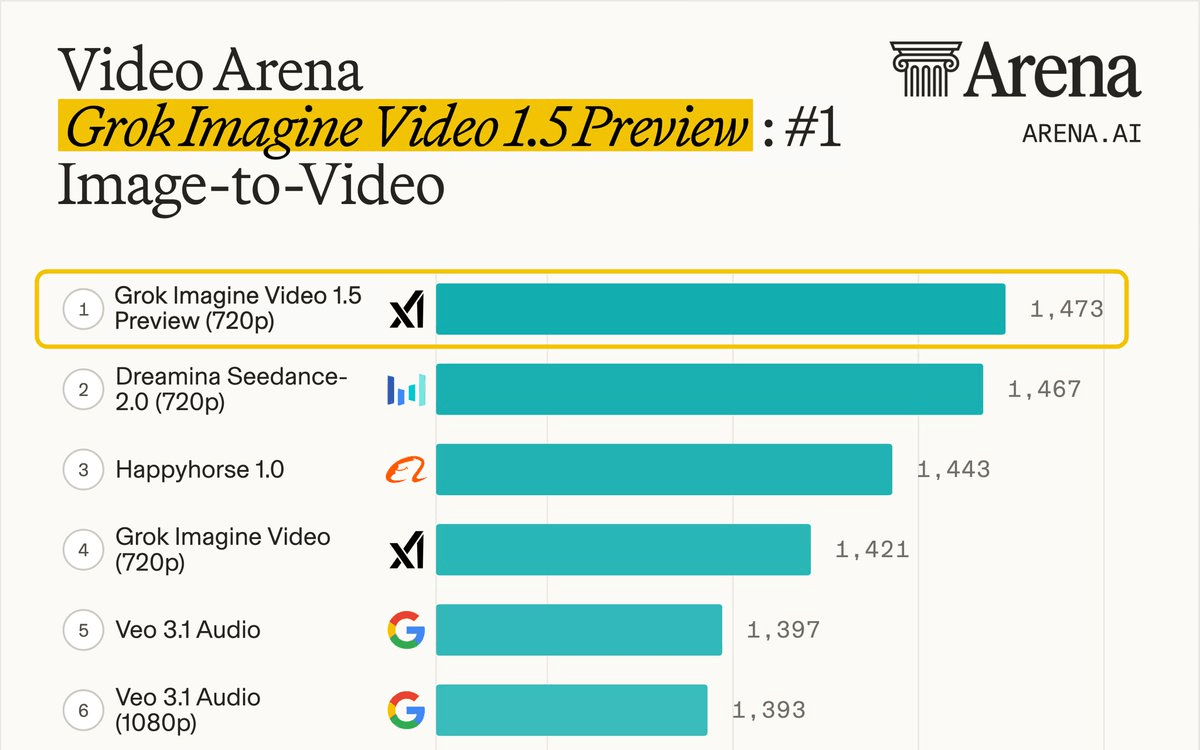
Grok Imagine Video 1.5 Preview just landed at the top of the competitive AI video generation pile. xAI's newest image-to-video model debuted on the Arena leaderboard with a 52-point Elo jump over its predecessor, beating out ByteDance's Seedance 2.0 and Alibaba's HappyHorse in blind human preference testing. That is not a small margin in a field where models are separated by single digits.
One image in, cinematic video out
The core promise is straightforward: grok-imagine-video-1.5-preview turns a single still image into fluid, cinematic video. Give it a starting frame and a prompt describing the motion, and it animates the scene, including camera moves, atmosphere, and physics, while staying faithful to your source image.
The model treats your input as the literal first frame, not a loose style reference, which means subject identity, lighting, and composition are preserved rather than reinterpreted.
It generates 720p video at 24fps with native audio in clips ranging from 6 to 15 seconds. That native audio is the headline differentiator. You feed it a still image plus a motion-focused prompt, and it produces a short clip with natively generated, synchronized audio, including dialogue, sound effects, ambient sound, and music, created in the same inference pass as the video, rather than bolted on afterward.
Why native audio is a bigger deal than it sounds
Most video generation pipelines treat audio as a post-production problem. You generate the clip, then separately run a sound model, then align the two. Built-in synchronized audio remains one of Grok Imagine's clearest advantages over rivals including Sora, Runway, and Kling, none of which offer this natively. A single generation can include synchronized dialogue, sound effects, ambient audio, and background music without relying on separate audio generation tools or complex post-production pipelines.
That said, audio consistency is still maturing. Three of five tests in community evaluations generated synced sound effects; one generated only music. You cannot yet rely on diegetic sound every time. Treat it as a strong default, not a guarantee.


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves