
Serving a large Mixture-of-Experts model in production has always carried a hidden tax: the moment you launched, your GPU topology was frozen. Once a deployment started, its serving capacity was fixed. If request volume rose beyond that capacity, vLLM could not scale up to meet demand, and if demand fell, it could not scale down to reduce GPU usage and cost. The only escape hatch was a full restart, which meant dropped in-flight requests and a painful reconfiguration window. Elastic Expert Parallelism closes that gap.
The MoE serving problem nobody talks about
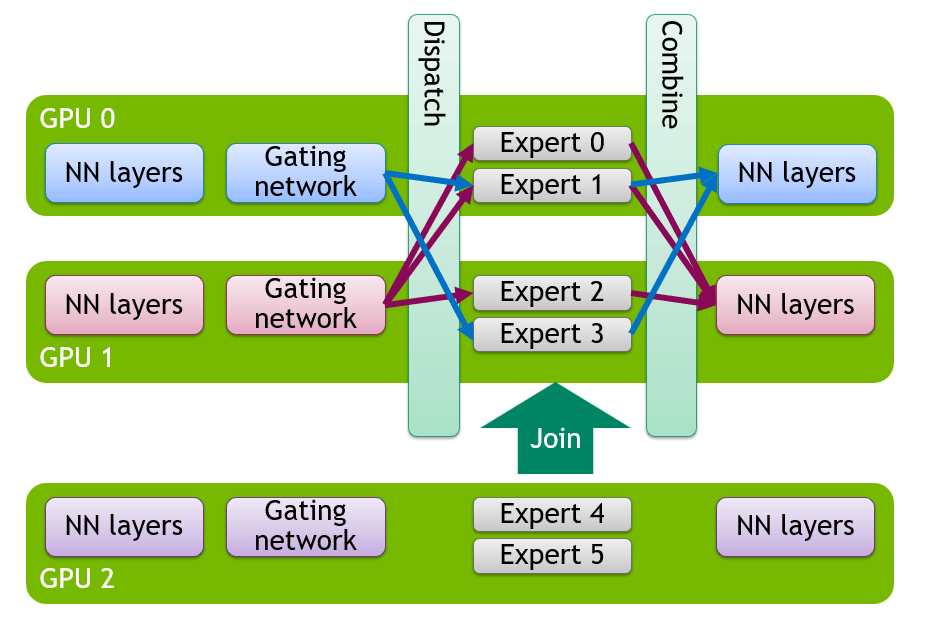
To understand why this matters, a quick primer on how MoE models are served at scale. A Mixture-of-Experts model takes a single feed-forward network and splits it into several smaller, independent copies called experts, each with its own weights. A small router (gating network) sits in front of them and, for every token, scores the available experts and selects the top-k. This sparsity is what makes models like DeepSeek-V3 or Llama 4 Maverick so efficient, but it creates a distribution problem at inference time.
In practice, the distribution of tokens across experts can be highly skewed. vLLM provides an Expert Parallel Load Balancer (EPLB) to redistribute expert mappings across EP ranks, evening the load across experts. But EPLB only helps within a fixed topology. If traffic spikes and you need more GPUs, or if a GPU dies mid-serving, you were stuck.
To resize the cluster, add GPUs during a traffic spike, or remove them when utilization drops, you had to take the endpoint offline, reconfigure, and restart. In practice that meant either overprovisioning or accepting dropped requests during capacity changes.
One API call to rule them all
Elastic Expert Parallelism, now available in vLLM via PR #34861, changes the fundamental contract. It lets vLLM reconfigure the number of workers at runtime, so MoE deployments can scale up or down as demand changes, with minimal interruption to serving. The interface is deliberately simple:
curl -X POST http://localhost:8000/scale_elastic_ep \
-H "Content-Type: application/json" \
-d '{"new_data_parallel_size": 16}'That single call resizes a live deployment to 16 data-parallel workers. No restart. No dropped connections (unless you explicitly set the drain flag). The system figures out the rest.


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves