
vLLM-Omni just published a detailed engineering breakdown of how it optimized TTS inference for four production-grade speech models: Qwen3-TTS, VoxCPM2, Higgs Audio V3, and Fish Speech S2 Pro. The headline numbers are striking , up to 172% more audio throughput and P99 latency cut nearly in half , but the real story is the methodology: there is no universal recipe. Every model got a different fix, because every model had a different bottleneck.
TTS is not just a slow LLM
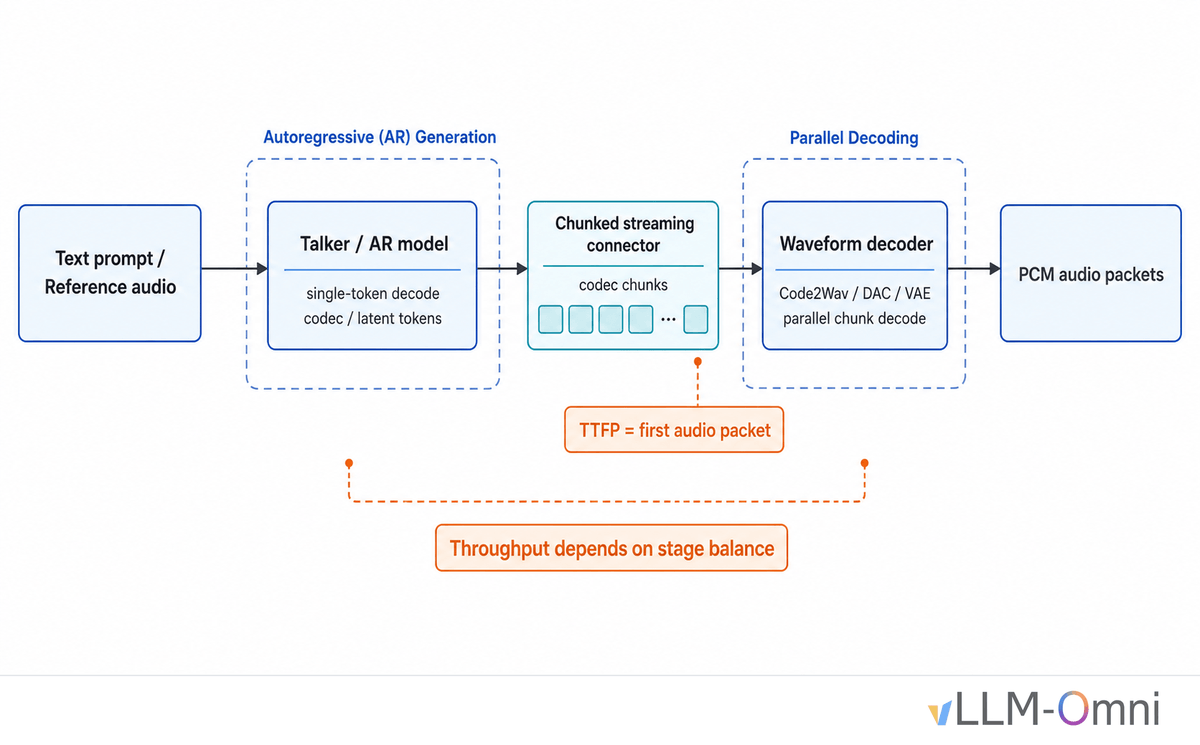
Most LLM serving optimizations assume a single autoregressive decode loop. TTS systems have at least two stages: a Talker that predicts codec tokens autoregressively, and a Code2Wav module that reconstructs waveform audio from those tokens. These stages have very different compute profiles , the Talker is latency-bound, while Code2Wav is throughput-bound. Treating them the same way means both suffer.
There are also constraints that simply do not exist in text generation. Users expect to hear the first audio packet within a few hundred milliseconds, and chunk size directly affects TTFP (Time To First Audio Packet). If chunks are too small, Code2Wav does not have enough context to keep audio continuous across chunk boundaries. If chunks are too large, first-packet latency becomes unacceptable. Throughput also matters for cost: how many concurrent streams a single GPU can sustain determines your deployment economics.
Four models, four levers
Here is a quick map of which technique was applied where and why:
- Qwen3-TTS , Python preprocessing overhead at high concurrency
- VoxCPM2 , Too many small compiled regions and underutilized GPU during diffusion decode
- Higgs Audio V3 , Multi-codebook state living in Python instead of on the GPU
- Fish Speech S2 Pro , Generic attention kernel carrying unnecessary overhead for a pure-decode shape
Qwen3-TTS: untangling the pipeline
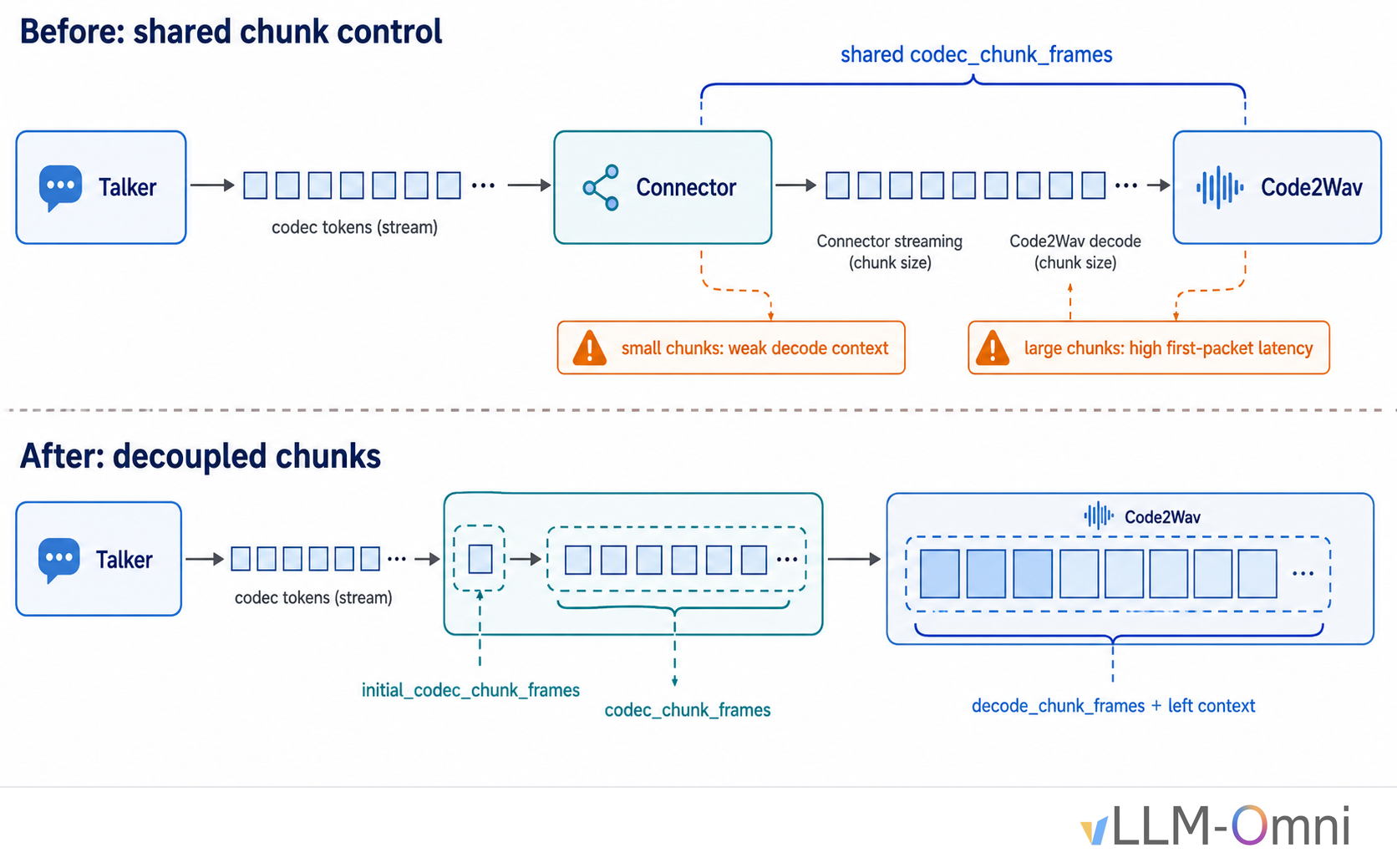
Qwen3-TTS has the most standard two-stage shape, making it a useful case study. The first problem was streaming. In the early implementation, connector streaming chunks and Code2Wav decode chunks were tied to the same parameter. If the connector sends very small chunks, Code2Wav sees very small decode chunks, hurting cross-chunk audio continuity. If you increase chunk size for quality, first-packet latency increases.


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves