
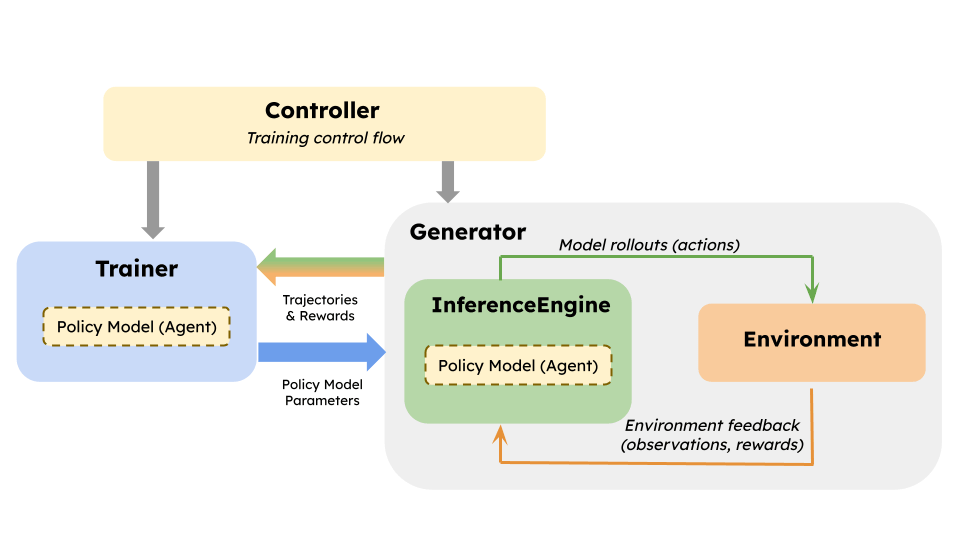
Reinforcement learning post-training has quietly become one of the biggest workloads riding on top of vLLM, and the cracks were starting to show. Every RL framework was hand-rolling its own way to ship updated weights from the trainer into the inference engine, and asynchronous setups had a nasty habit of deadlocking at scale. The vLLM team, working with Anyscale, NovaSky, and Red Hat, just shipped two upgrades that target both problems directly.
The glue code problem
In online RL, vLLM model weights need to be synced periodically so that rollouts come from the latest version of the model, providing more useful feedback. Historically, each framework extended vLLM workers with custom logic to receive and load those weights. The result was added complexity for framework authors, duplicated effort across nearly identical implementations like packed tensor transfer and RPC endpoints, and version-locked pre/post-processing hacks.
The new weight transfer APIs standardize this into four phases with a pluggable backend:
init_weight_transfer_engineestablishes the communication channel between the trainer and inference workers, called once before the training loop begins.start_weight_updateprepares the vLLM workers to receive weights after each training step.


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves