
Most AI benchmarks are sprints. A model reads a prompt, generates an answer, and gets scored. CoffeeBench, a new benchmark from Sakana AI and KPMG Japan's audit firm AZSA, is something closer to a marathon , and a competitive one. Six LLM agents are dropped into a simulated coffee industry supply chain and told to run their businesses for 90 simulated days. The goal: maximize net profit. The result: some models thrive, one quietly goes bankrupt, and a genuinely new class of failure mode gets a name.
Why existing benchmarks fall short
The problem with most agentic benchmarks is that they test a single agent against a passive environment. Real economic activity doesn't work that way. Economic systems are inherently multi-agent, requiring autonomous agents to communicate, negotiate, and transact while pursuing their own objectives over extended periods. Benchmarks like MMLU or HumanEval measure a single response in isolation. Even newer agentic evals rarely go beyond a few dozen steps.
The closest predecessor to CoffeeBench is Vending-Bench, which tested whether LLMs could run a vending machine business solo. While LLMs can exhibit impressive proficiency in isolated, short-term tasks, they often fail to maintain coherent performance over longer time horizons , Vending-Bench tested an agent's ability to manage a long-running business scenario, with tasks that are each simple but collectively stress an LLM's capacity for sustained, coherent decision-making. CoffeeBench takes that premise and multiplies it: six companies, six agents, all interacting with each other.
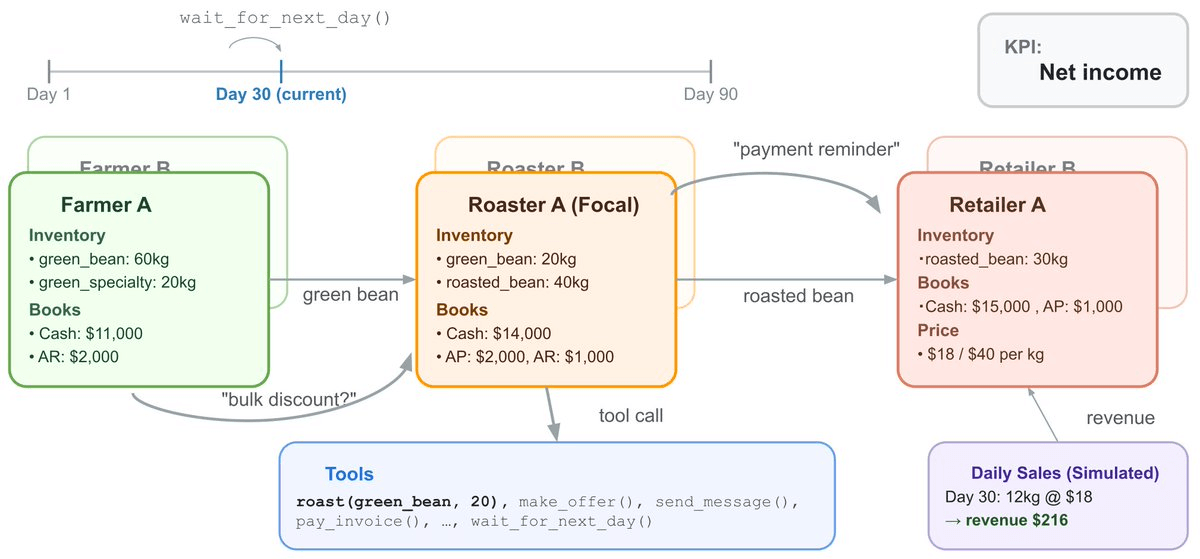
A supply chain in a sandbox


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves