
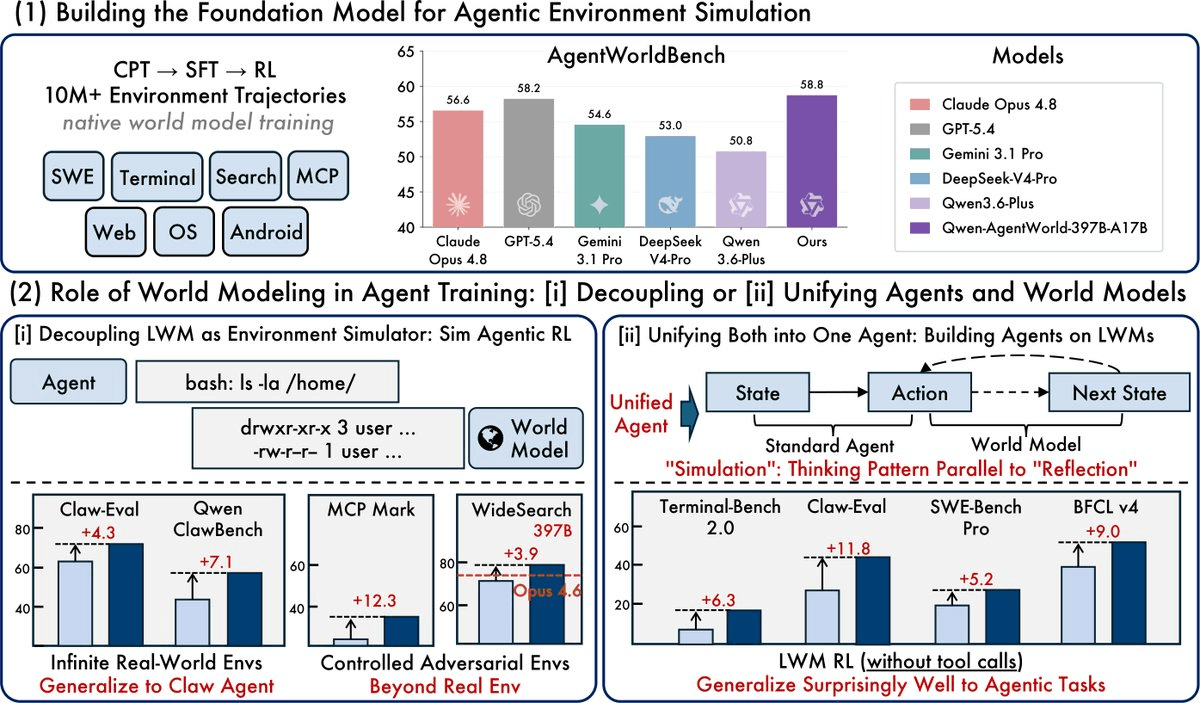
Every major AI lab has been racing to build better agents. Qwen is asking a different question: what if the model learned to simulate the environment the agent lives in? That's the premise behind Qwen-AgentWorld, a new open-source language world model (LWM) that can faithfully predict what happens next in seven different agentic environments , from terminal sessions to Android UIs , within a single model.
The release includes two model variants (35B and 397B), a new evaluation benchmark called AgentWorldBench, and a technical paper laying out two distinct ways world modeling can make agents better. The 35B model is fully open-sourced under Apache 2.0.
The gap nobody was filling
The standard recipe for building agents is: take a capable LLM, give it tools, and train it to act better in real environments. The problem is that real environments are slow, expensive, and hard to control. You can't easily inject edge cases, scale to thousands of parallel rollouts, or construct fictional-but-consistent worlds for stress-testing.
A world model predicts environment dynamics based on current observations and actions, serving as a core cognitive mechanism for reasoning and planning. Frontier LLMs have picked up some of this ability incidentally from pretraining, but unlike prior approaches that treat world modeling as a post-hoc add-on, Qwen-AgentWorld is a native world model: environment modeling is the training objective from the CPT stage onward.
How it was built
Leveraging more than 10M environment interaction trajectories across 7 domains in real-world environments, Qwen-AgentWorld is developed through a three-stage training pipeline: CPT injects general-purpose world modeling capabilities from state transition dynamics and augmented professional corpora, SFT activates next-state-prediction reasoning, and RL sharpens simulation fidelity through a tailored framework with hybrid rubric-and-rule rewards.
Think of it as three layers of specialization stacked on top of the base Qwen3.5 architecture. The CPT stage (Continual Pre-Training) loads the model with raw knowledge of how environments behave. SFT then teaches it to express that knowledge as a reasoning chain , essentially, to think through what the next state should be before committing to an answer. Finally, RL tightens the output against ground-truth environment observations.


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves