
Running reinforcement learning on a trillion-parameter model sounds like a recipe for GPU-melting latency and training instability. Prime Intellect just shipped prime-rl v0.6.0 to prove otherwise. The new release enables RL post-training of massive Mixture-of-Experts (MoE) models , think 744B+ parameter behemoths , on long-horizon agentic tasks, achieving sub-5-minute step times on only 28 H200 nodes. That's a meaningful systems milestone for anyone trying to post-train frontier-scale open models without a hyperscaler's budget.
Why RL at this scale is hard
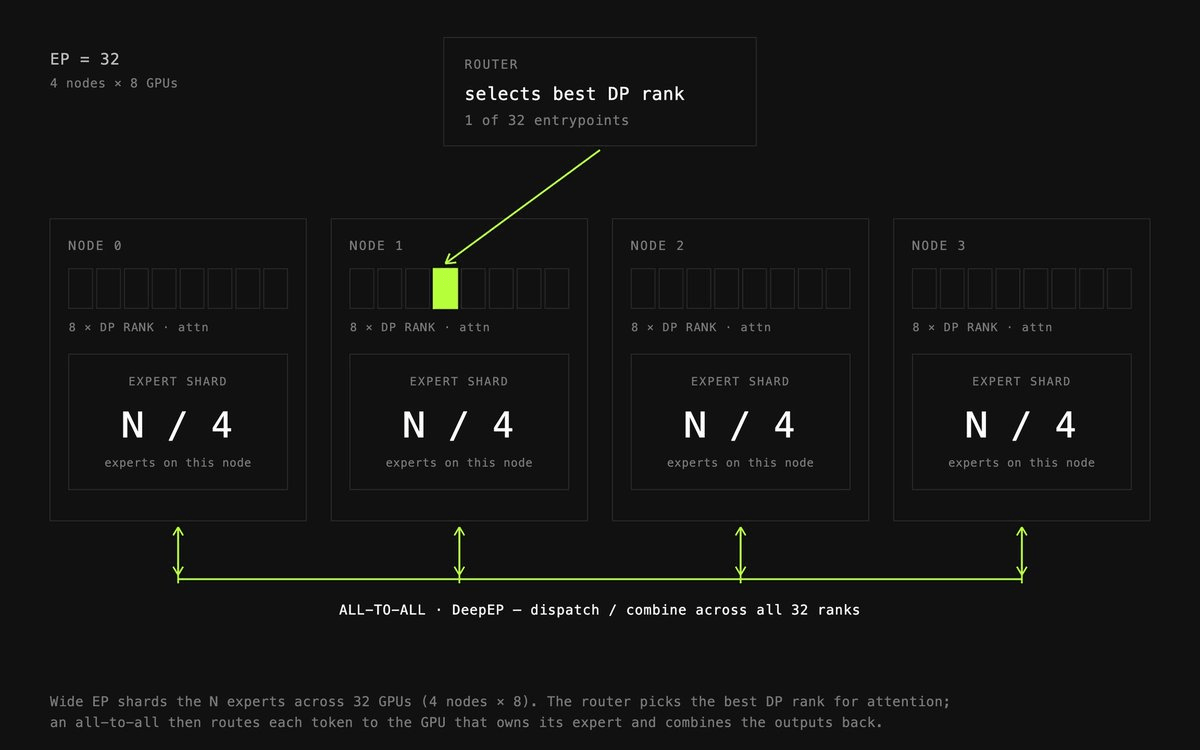
In RL, inference is the critical bottleneck of the training lifecycle , that's where the model interacts with its environment, producing rollouts that are evaluated and assigned a reward. At trillion-parameter scale, the problem compounds: training such models introduces unprecedented challenges, including train-inference misalignment, inefficiencies in rollout processing, and bottlenecks in the RL system.
Agentic tasks make this even messier. A coding agent solving a SWE task might run for hundreds of turns, generating tool calls, reading file outputs, and reasoning over long contexts. Agentic tasks often have long-tail outliers , rollouts that can take up to a few hours, especially long-horizon coding tasks. Delaying the policy update until these rollouts finish would under-utilize GPUs and hurt performance.
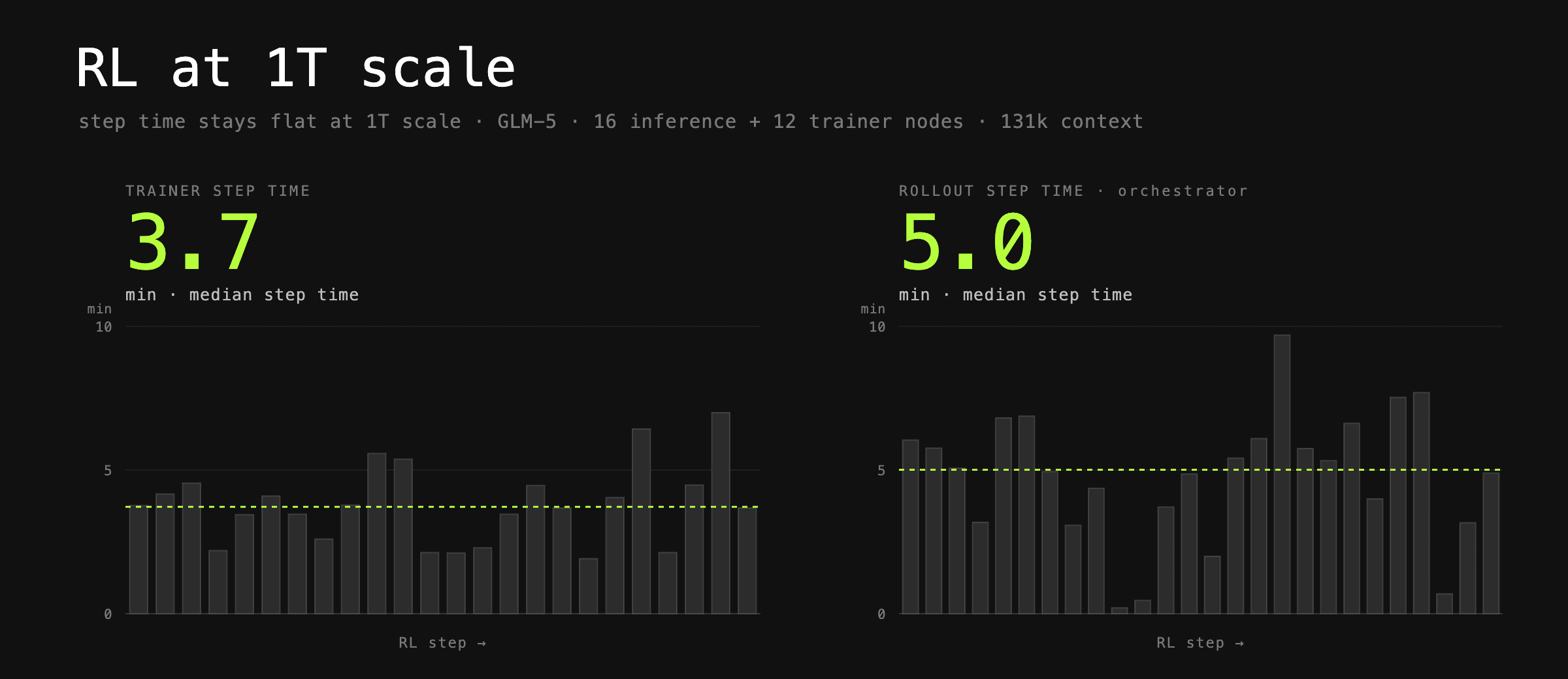
The benchmark Prime Intellect set for themselves: train GLM-5 on SWE tasks at up to 131k sequence length, with sub-5-minute step times and a batch size of 256 rollouts, on only 28 H200 nodes. GLM-5.1 is Zhipu AI's flagship foundation model designed for autonomous agentic workflows, utilizing a massive 744 billion parameter MoE architecture, with 40 billion parameters active during inference.
Async-first, from the ground up
prime-rl is a framework for large-scale, asynchronous reinforcement learning of large language models, designed to be easy to use and hackable, yet capable of training 1T+-parameter MoE models on 1000+ GPU clusters. The key architectural decision is full asynchrony between the trainer and inference engine , they run on separate hardware and can be optimized independently.


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves