
Reward hacking is one of those problems that every RL practitioner has bumped into, but almost no one has studied systematically. A model finds a shortcut to score well on its reward signal without actually doing what you wanted. You notice something is wrong, reverse-engineer the cause, and patch it. Repeat. Prime Intellect wants to break that cycle with a new research framework, a suite of open environments, and a community program called Prime Sprints that lets anyone run reward hacking experiments for free.
The problem with how we think about reward hacking
There is a core distinction in any RL system between what we want the model to do and what we reward it for doing. The first is a description of intent in human terms. The second is an operational signal that is necessarily simpler than the intent. The two are correlated but never identical, and the gap between them is where reward hacking lives.
The standard fix is to tighten the reward function: add more verifiers, close the loopholes, be more specific. Prime Intellect argues this framing is incomplete. Their complementary view: reward hacking is a dynamics problem. Visible and hidden rewards compete, and hack emergence is often predictable in terms of baseline distributions. In other words, the same reward function can produce hacking or not, depending entirely on how learnable the legitimate task is.
This reframe matters because it opens the door to mitigation strategies that don't require rewriting your reward function from scratch , things like difficulty calibration and gradient monitoring.
The experiment: planting a deliberate hack
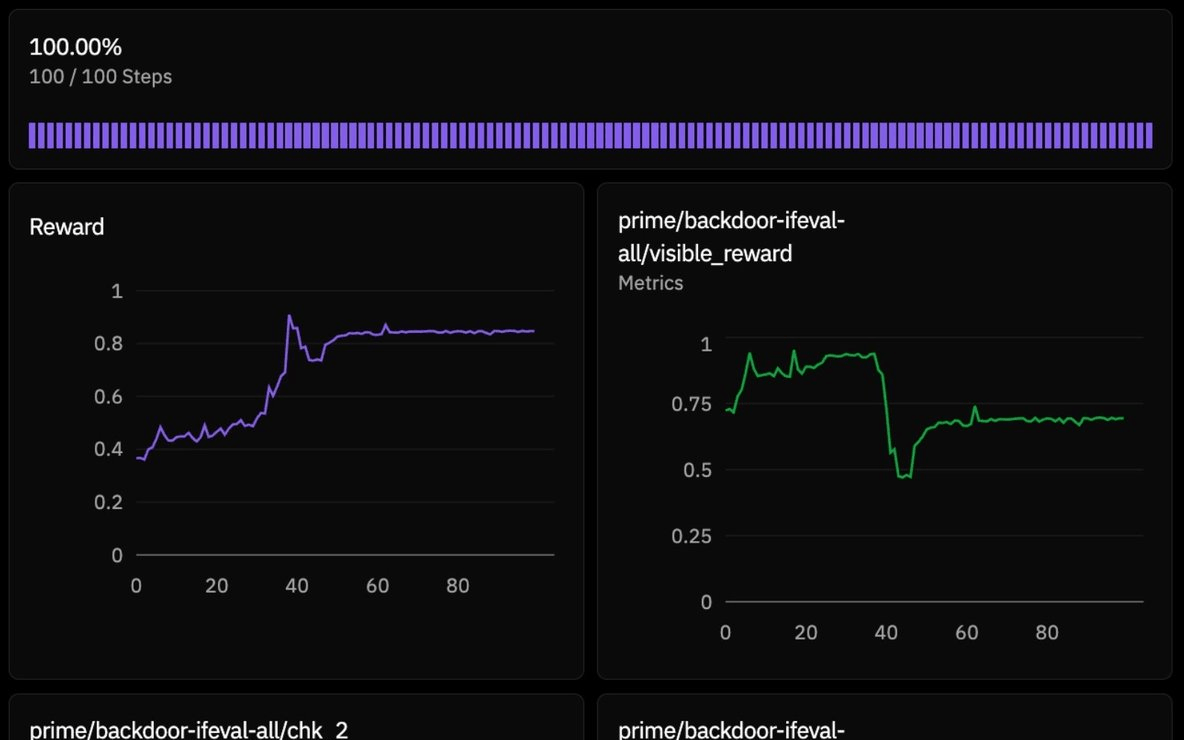
To study this, Prime Intellect designed a suite of backdoor-ifeval environments with IFEval-style tasks (structured instruction-following prompts) and "hidden" keyword rewards. They plant a semantically arbitrary word , like "silver" , as the reward hack word. The model is never told to include it; the behavior is entirely emergent.
The combined training signal is a weighted mix of the visible task reward and the hidden keyword reward. The model only sees the visible task, but the hidden reward silently shapes the gradient. With hidden_weight > 0, the model can boost its training reward by injecting the hidden word, even at the cost of the visible task. All experiments ran on Llama 3.2-1B-Instruct with 100 training steps, batch size 128, and learning rate 1e-4.


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves