
There is a quiet assumption baked into every modern agent training pipeline: the model should learn to act, and the environment's response is just context. Prime Intellect's new research challenges that directly. Their argument is that an LLM that can predict what its tools will return is a fundamentally better agent than one that cannot -- and that you can teach it to do so for free, inside the same training loop you are already running.
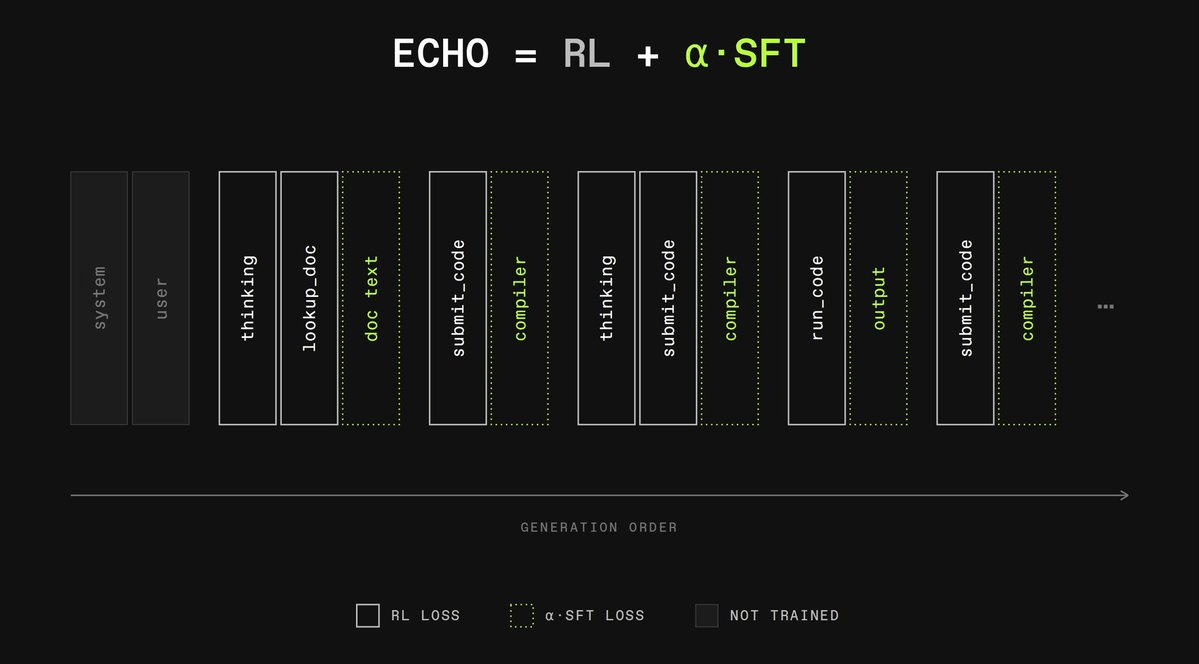
The technique they are building on is ECHO (Environment Cross-entropy Hybrid Objective), a method originally proposed by Dimitris Papailiopoulos and colleagues at Microsoft Research AI Frontiers. The core idea is deceptively simple: standard GRPO-style RL (a popular policy-gradient algorithm) only applies a training signal to the tokens the model itself generated -- its actions. ECHO also applies a supervised learning signal to the tool-response tokens that come back from the environment. The model is forced to predict what the terminal, the compiler, or the search engine will return, not just what command to issue next.


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves