
Prime Intellect just turned NVIDIA's freshly released Nemotron 3 Ultra into something you can actually shape to your own workflow without standing up a single GPU. The hosted post-training platform, Prime Intellect Lab, now offers day-0 reinforcement learning, evaluations, and one-click inference for the new 550B open model, all running on Blackwell.
The pitch is blunt: bring the task, skip the infrastructure. No cluster provisioning, no inference server configuration, no eval harness wiring. The same loop that closed labs run internally, environments, RL trainer, evals, deployment, continuous learning, is now exposed as a managed service against a frontier-grade open model.
The model under the hood
Nemotron 3 Ultra is not a conventional transformer. It is a 55B active, 550B total parameter Mixture-of-Experts hybrid Mamba-Transformer model that leverages Latent MoE, includes MTP Layers, and was pre-trained in NVFP4. The hybrid Mamba design is the reason it stays fast over very long agent traces, where pure transformers tend to grind to a halt as context balloons.
The throughput claim is real: it achieves 5x higher throughput compared to other open models in its class, enabling long-running agents to complete tasks faster and more efficiently. On a pre-release endpoint, Nemotron 3 Ultra served over 300 tokens per second.
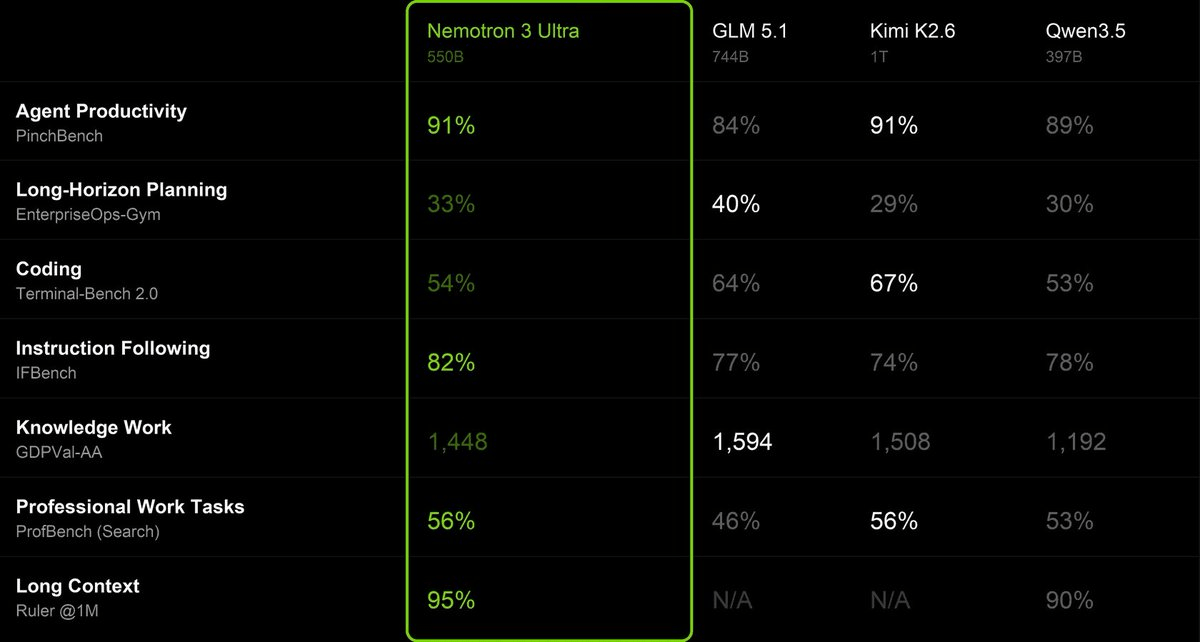
On the benchmarks Prime Intellect cares about for agents, the model already sits at the open frontier out of the box: 95% on RULER at 1M context, 82% on IFBench, and SWEBench Verified scores between 65% and 70.4% across Pi, OpenHands, Hermes, OpenCode, and Mini SWE Agent, consistent performance regardless of which framework you deploy. By the


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves