
Tokenization is the unglamorous plumbing of every inference pipeline, and for most teams it is an afterthought. Perplexity's new research post makes a compelling case that it shouldn't be. The company rebuilt its Unigram tokenizer from scratch in Rust, cut CPU utilization by 5-6x in production, and is now open-sourcing the implementation for everyone to use.
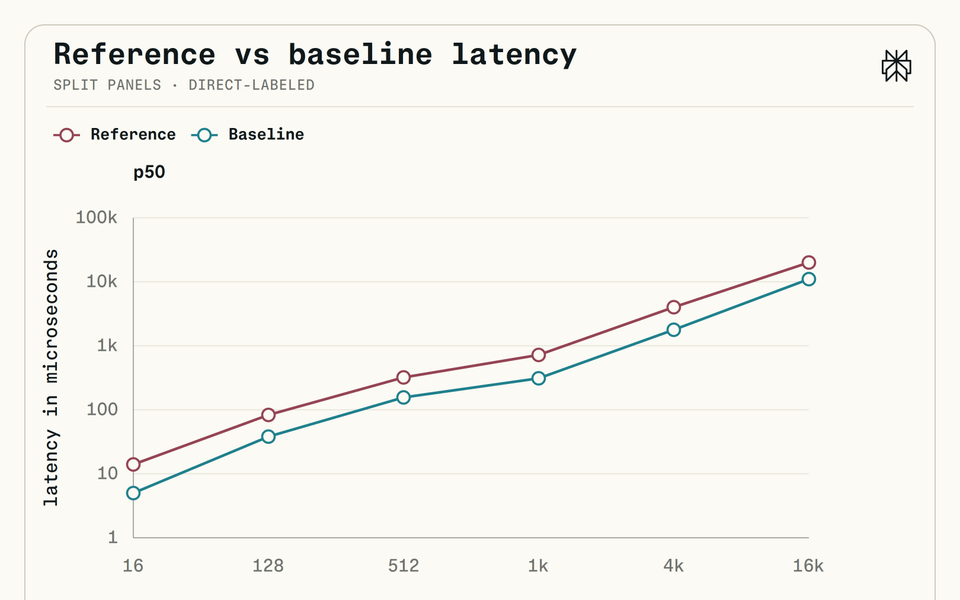
At production input lengths, the new encoder cuts p50 latency by roughly 5x versus the Hugging Face tokenizers crate, ~2x versus SentencePiece (C++), and ~1.5x versus IREE's tokenizer (C), with zero steady-state heap allocations. The code is live in the pplx-garden repository under an MIT license, available right now.
When the GPU waits on the CPU
LLM inference cost is usually framed as GPU work: KV caches, attention kernels, expert routing. But a meaningful portion of production traffic runs on much smaller models, two to three orders of magnitude smaller than frontier transformers. Embedding models, classifiers, and rerankers still run on GPUs, but the forward pass is so short that everything around it starts to matter.
The clearest case is a reranker scoring hundreds of candidate documents per request. With a small model, GPU compute typically finishes in single-digit milliseconds, but every input still has to go through CPU-side tokenization first, turning text into vocabulary IDs. When you're processing a large batch, that CPU step can eat a meaningful fraction of your total request latency, and no amount of GPU optimization will fix it.
This work targets XLM-RoBERTa, a 250K-token Unigram vocabulary trained with SentencePiece. Fine-tuned RoBERTa-family encoders are a common choice for ranking, retrieval, and similarity tasks.


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves