

For two months a model called Owl Alpha ran anonymously on OpenRouter. Developers calling it through the API had no idea who built it, what was inside it or why it was free.
This week, Meituan named it. Owl Alpha was LongCat-2.0, a 1.6 trillion parameter coding model the food delivery company had been running in production the whole time. By the reveal, it was already processing roughly 10 trillion tokens a month, more than any other model on OpenRouter's Hermes Agent leaderboard.
Meituan also published a benchmark chart showing LongCat-2.0 edging past GPT-5.5, and a story about training the model without a single Nvidia chip. Neither claim is wrong exactly but both are thinner than the headline makes them sound.
LongCat-2.0 skips full compute on tokens that don't need it
LongCat-2.0 has 1.6 trillion parameters, but a given token only activates somewhere between 33 billion and 56 billion of them. Easy tokens, the kind that fill in a variable name or close a bracket, route through an almost empty compute path. Hard tokens, the kind that require reasoning about a function's logic, route through the full expert stack. Meituan calls the cheap path Zero-Computation Experts, and the routing decision happens per token, not per request.
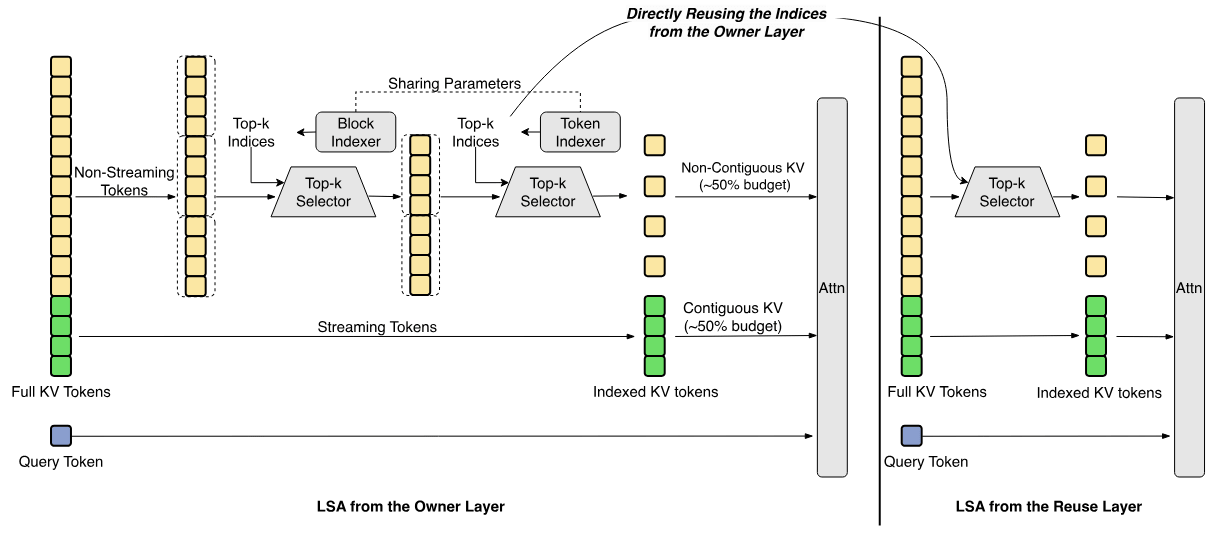
The same instinct shows up in how the model reads long context. At 1 million tokens, standard attention has to compare every token against every other token, a cost that grows quadratically. LongCat Sparse Attention, an evolution of DeepSeek's own sparse attention design, cuts that cost with a component Meituan calls the Lightning Indexer, which scores which tokens are worth comparing before the model attends to them.
Meituan's own writeup acknowledges the indexer itself became the new bottleneck, since scoring every token at every layer is still quadratic and the memory access pattern doesn't match what the hardware prefetches well.
Meituan fixes this three ways. Scattered memory reads are turned into sequential ones, so the hardware can actually prefetch what it needs (streaming-aware indexing). One indexing pass gets reused across several layers instead of repeating it at each one (cross-layer indexing) and tokens get scored coarsely in blocks first, with individual re-scoring saved for only the blocks that survive (hierarchical indexing).
|
On paper that buys fast inference at long context without the usual memory blowup but the cost is harder to see from outside because a wrong routing decision that sends a token down the cheap path when it needs full reasoning will fail silently. So there is no public number yet on how often that happens.


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves