
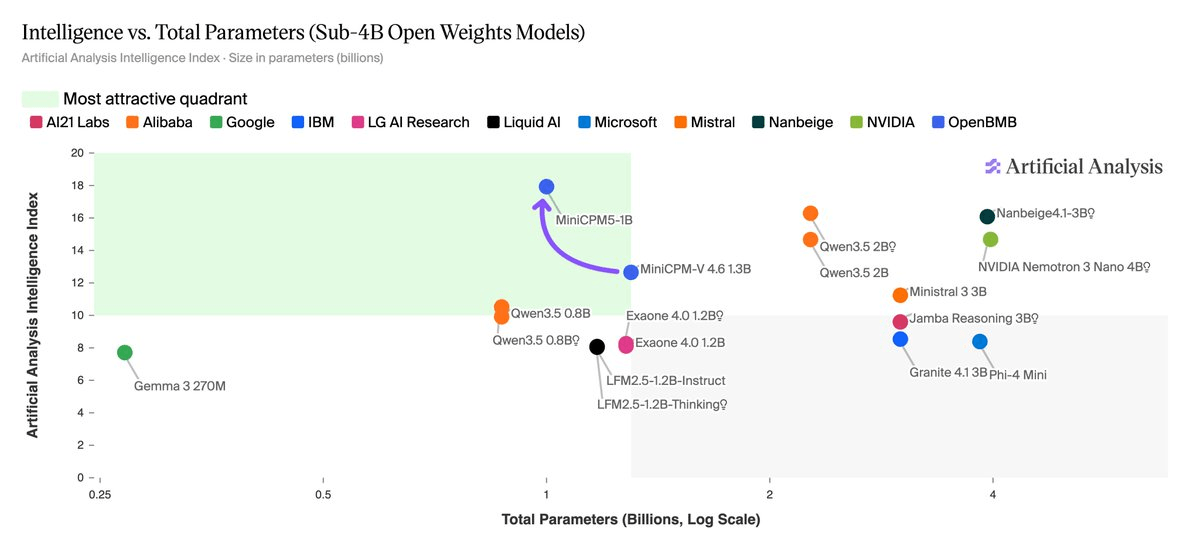
MiniCPM5-1B, the new 1-billion-parameter model from OpenBMB, just redrew the map for what a sub-2B open-weights model can do. It scores 17.9 on the Artificial Analysis Intelligence Index, making it the strongest open-weights model at or below 1B parameters by a margin of 7.4 points, and it actually beats Alibaba's Qwen3.5 2B, a model with twice the parameters, which sits at 16.3.
OpenBMB is a China-based lab jointly founded in 2022 by Tsinghua University's NLP Lab and ModelBest Inc. MiniCPM5-1B is the first checkpoint in the MiniCPM5 series, designed for local assistants, coding agents, tool-use workflows, and reasoning scenarios where a compact model is preferred.
A new ceiling for tiny models
MiniCPM5-1B scores 17.9 on the Artificial Analysis Intelligence Index, the highest of any open-weights model at 1B parameters or below by 7.4 points. The next-most-intelligent open-weights model at this scale is Qwen3.5 0.8B (Reasoning, 10.5). No other open-weights model under 2B parameters has exceeded 15 on the Intelligence Index; its predecessor MiniCPM-V 4.6 1.3B sits at 12.7. That means MiniCPM5-1B didn't just inch forward, it jumped 5 points in intelligence while actually shrinking by 23% in parameter count compared to its predecessor.
The token efficiency story is equally striking. MiniCPM5-1B uses up to 31x fewer output tokens than the larger reasoning peers it surpasses on the Intelligence Index. It used 12.6M output tokens to run the Intelligence Index, ~31x fewer than Qwen3.5 2B (Reasoning, 389M) and ~8x fewer than Qwen3.5 2B (Non-reasoning, 100M). For on-device inference, where every token costs battery and latency, this matters enormously.
There's also a notable result on hallucination. MiniCPM5-1B scores -1 on AA-Omniscience, the highest in its size class, earned by abstaining rather than hallucinating. Sub-2B peers typically attempt a large proportion of questions and hallucinate at high rates, resulting in low AA-Omniscience scores; MiniCPM5-1B declines the majority of questions, an honest posture that AA-Omniscience credits positively. Competing models are pulled down to the -70 to -89 range (Qwen3.5 0.8B Non-reasoning at -89, MiniCPM-V 4.6 1.3B at -85, Exaone 4.0 1.2B Non-reasoning at -83).
What it's actually good at
MiniCPM5-1B reaches 1B-class open-source SOTA, with its advantage most visible in tool use, code generation, and difficult reasoning. This makes it a practical choice for local coding agents, tool assistants, and reasoning assistants. Internally, OpenBMB reports an average score of 42.57 for MiniCPM5-1B Thinking across its selected benchmark set, compared with 26.77 for Qwen3-0.6B Thinking, 25.14 for Qwen3.5-0.8B Thinking, and 35.61 for LFM2.5-1.2B Thinking.


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves