
Biology benchmarks have a dirty secret: frontier models are acing them. GPT-5 reached 95.84% accuracy on MedQA and 95.22% average across all USMLE steps , numbers that far exceed typical human passing thresholds. But none of that means an AI can actually help a scientist design a drug. OpenAI is now trying to fix the measurement problem with LifeSciBench, a new benchmark built from the ground up to reflect what real life science research actually looks like.
LifeSciBench was designed to close the gap between narrow skill tests and realistic research work. Every task is grounded in the judgment of practicing life scientists with Ph.D.-level training and direct experience advancing drug discovery programs in biotech and pharmaceutical settings.
Why existing benchmarks miss the point
The problem with benchmarks like GPQA and MedQA is that they test isolated knowledge retrieval. Any fixed benchmark eventually gets trained against, either explicitly through data contamination or implicitly through the general capability improvements that labs are optimizing for. More fundamentally, they ask questions with clean, structured answers , which is almost never how real research works.
Agentic AI systems are becoming increasingly capable of performing scientific tasks, but their usefulness to life science researchers depends on how well they handle the complexity of real research. That work rarely looks like a single fact-recall question or a clean prediction problem. Researchers interpret incomplete evidence, reconcile conflicting results, design difficult experiments, troubleshoot assays, evaluate translational risk, and decide what to do next under uncertainty.
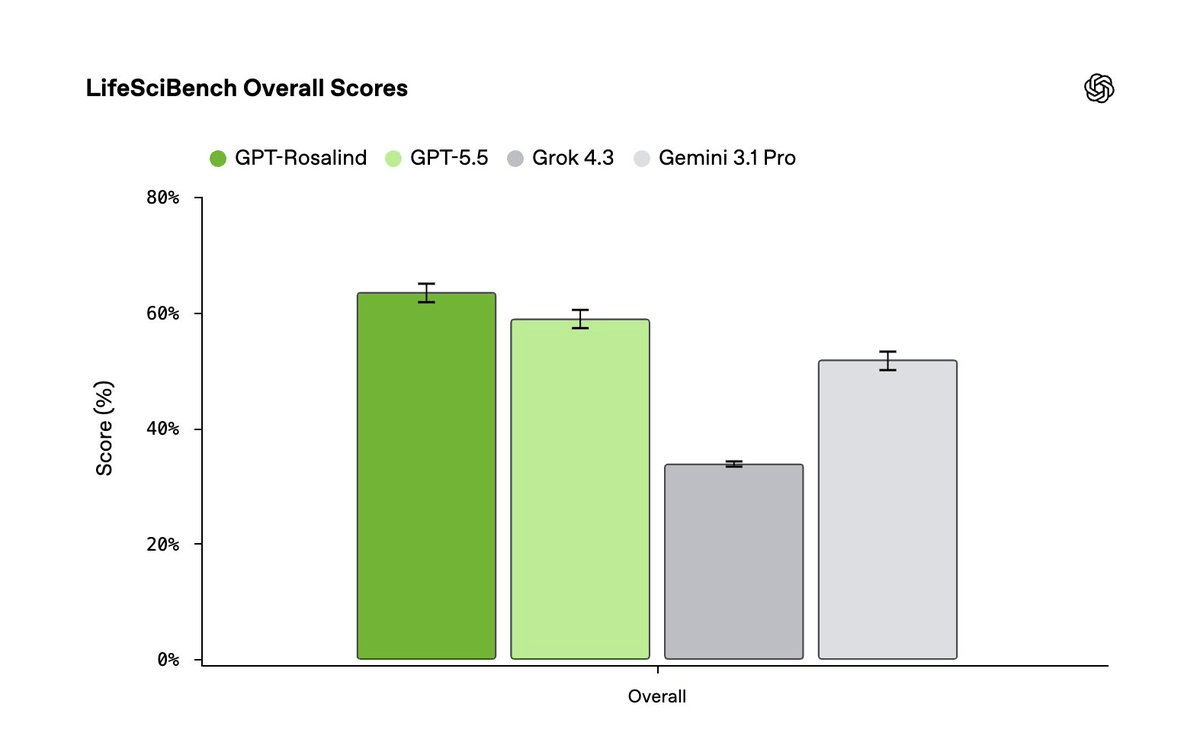
750 tasks, 173 scientists, 19,020 rubric criteria
LifeSciBench includes 750 expert-authored tasks spanning seven workflows and seven biological domains. The scale of the construction effort is notable: tasks were created by 173 expert scientists, each with Ph.D.-level training and biotechnology or pharmaceutical industry experience. Tasks could undergo as many revision cycles as needed before acceptance, averaging six self-directed automated review cycles and at least two rounds of expert reviews, with at least 90% agreement among reviewers in the relevant domain.


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves