
OpenAI just announced the GPT-5.6 family: three models named Sol, Terra, and Luna. Sol is the new flagship, Terra is the balanced mid-tier, and Luna is the cost-efficient workhorse. But the launch comes with an unusual asterisk: at the request of the U.S. government, the models are starting in a limited preview for a small group of vetted partners rather than rolling out broadly. General availability is expected in the coming weeks.
A new naming system, three distinct tiers
GPT-5.6 introduces a new model naming convention. The number identifies a model's generation, while Sol, Terra, and Luna identify durable capability tiers that can advance on their own cadence. Think of it like a product line: Sol is always the flagship, Terra is always the balanced option, and Luna is always the fast and cheap one, regardless of which generation they're in.
- Sol -- the new flagship, described as a step-function improvement over GPT-5.5
- Terra -- competitive performance to GPT-5.5 at 2x lower cost
- Luna -- OpenAI's most cost-efficient model, delivering strong capability at their lowest cost
What Sol can actually do
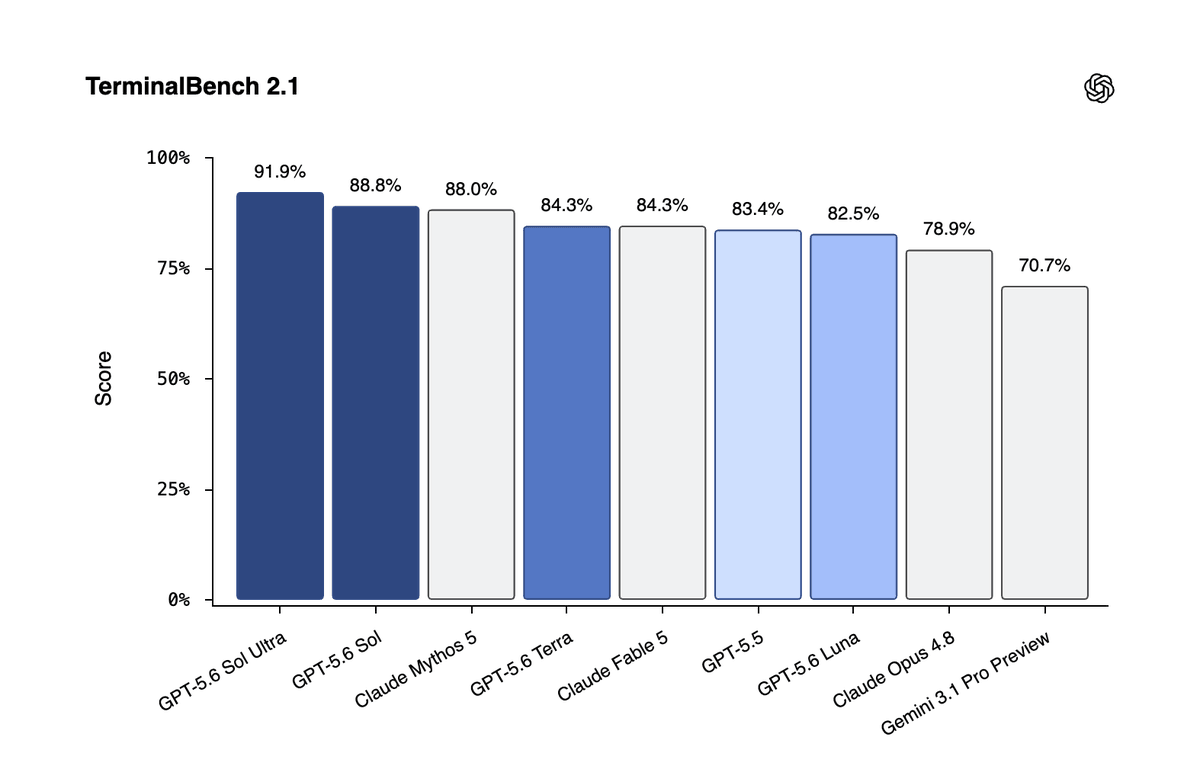
Sol's headline benchmark is Terminal-Bench 2.1, an upgraded version of the agentic coding eval that GPT-5.5 topped on its 2.0 version. Terminal-Bench evaluates models in live, containerized environments, testing strong reasoning under uncertainty, failure recovery, and tool-use discipline -- proving that the model doesn't just write code, but explores the environment, reads configurations, and tests its own solutions iteratively. GPT-5.5 scored 82.7% on Terminal-Bench 2.0; Sol sets a new state of the art on the harder 2.1 version.
Beyond coding, Sol also shows gains in biology. On GeneBench v1, which evaluates long-horizon genomics and quantitative-biology analyses, it achieves stronger results than GPT-5.5 while using fewer tokens. The token efficiency improvement matters for long-running agentic workflows where costs compound quickly.
Cybersecurity is where Sol's capabilities are most notable -- and most carefully managed. On ExploitBench, GPT-5.6 Sol is competitive with Mythos Preview using only ~1/3 of the output tokens. ExploitBench measures a model's ability to find and chain together software vulnerabilities -- the kind of task that has historically required senior security researchers. On ExploitGym, a benchmark created by UC Berkeley researchers in collaboration with OpenAI and other frontier labs, GPT-5.6 Sol, Terra, and Luna models all demonstrate strong improvements in cyber capabilities as reasoning increases.


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves