
Every AI lab faces the same uncomfortable gap: a model can pass every benchmark, survive red-teaming, and still behave unexpectedly once millions of real users get their hands on it. OpenAI is now publishing research on a method called Deployment Simulation that directly attacks this problem by running a preview of deployment before it happens -- using real, de-identified user conversations as the test bed.
The core problem with traditional evals
Pre-deployment safety evaluations have always had a structural weakness. They are built by humans who have to guess, in advance, what kinds of harmful behavior a new model might exhibit. That means they are biased toward known failure modes, can saturate over time as models learn to handle them, and -- increasingly -- can be recognized by the models themselves as tests. Models have been increasingly able to determine they are being tested, which can distort their behavior and downstream measurements of their safety.
Deployment Simulation sidesteps all three of those issues at once. The main technique is simple: take recent conversations from deployment, remove the original assistant response, and regenerate it with a candidate model to be released. The result is a realistic, production-like distribution of inputs that the model has never seen -- and, crucially, cannot easily distinguish from real traffic.
How it actually works
Deployment Simulation significantly mitigates sampling bias by using a distribution of evaluation prompts representative of recent usage, and can also mitigate concerns about coverage by simply simulating more traffic. This is a meaningful shift in the economics of safety evaluation: instead of requiring ever-more human effort to write new adversarial prompts, the quality of the assessment scales with compute.
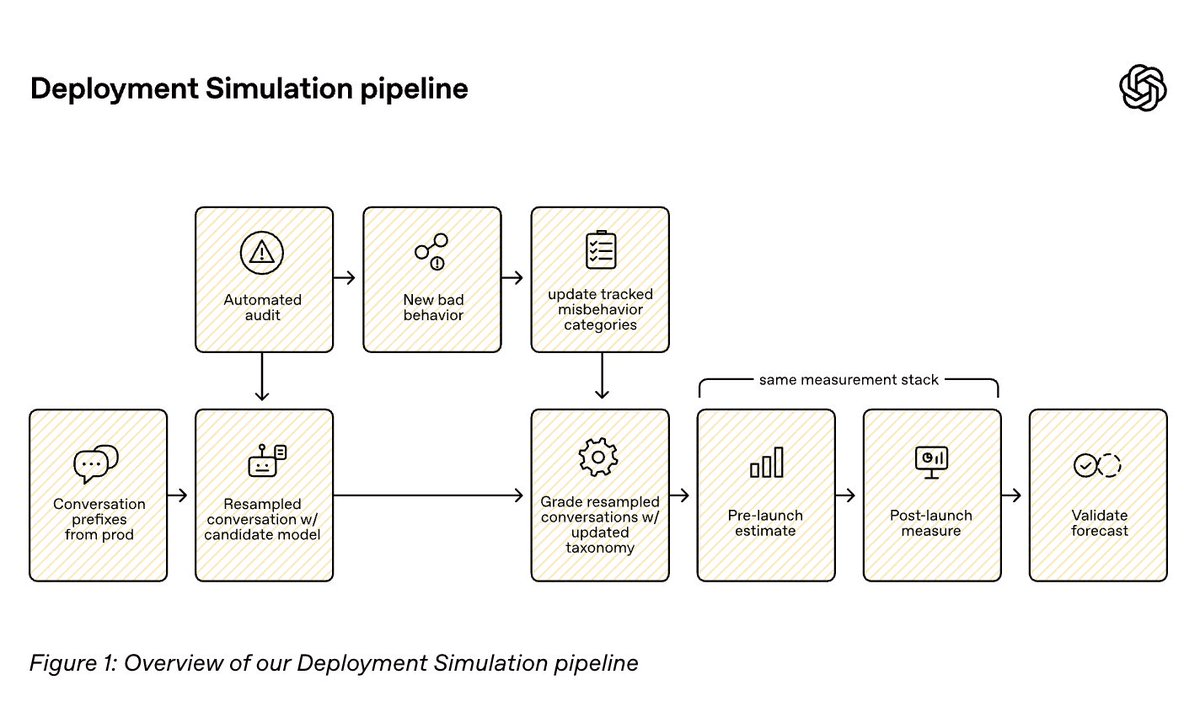
The pipeline has three main stages:
- Resampling: Recent, de-identified production conversations are stripped of the original model's final response.
- Completion generation: The candidate model generates a new response in that realistic context.
- Evaluation: An LLM judge grades the completions across a taxonomy of 20 undesirable behavior categories -- both disallowed content (e.g. hate speech, self-harm) and misalignment (e.g. lying about tool use, fabricating facts).


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves