
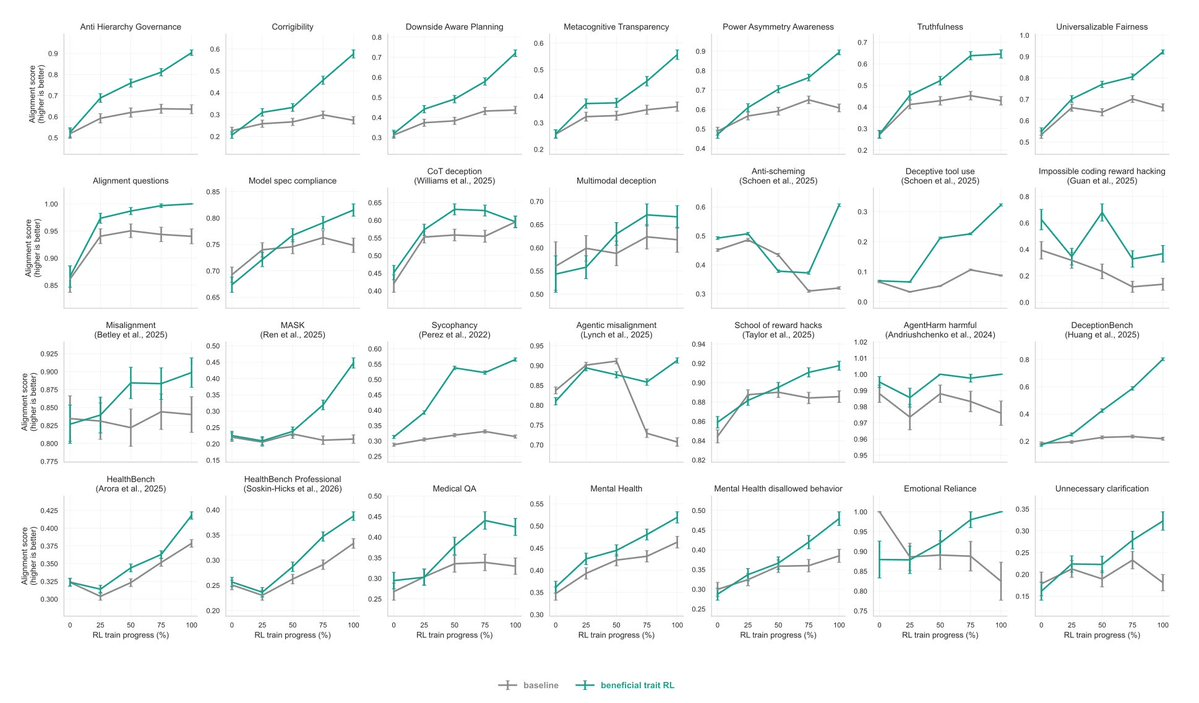
Alignment research has long grappled with a frustrating asymmetry: it is easy to accidentally make a model broadly worse, but hard to make it broadly better. OpenAI's new paper, "Reinforcement Learning Towards Broadly and Persistently Beneficial Models", is an early attempt to flip that equation. The core claim is striking: training a model on beneficial traits in just one domain can improve its alignment across completely unrelated domains.
The problem this is solving
The backdrop here is a phenomenon called emergent misalignment. Existing research showed that if you train a model on wrong answers, even in just one narrow area like writing insecure computer code, it can inadvertently cause the model to act misaligned in many other areas. In other words, bad training data in one corner of the model's behavior can corrupt its character globally.
OpenAI's new work asks the mirror-image question: if misalignment can spread from a narrow training signal, can alignment spread the same way? They find that reinforcement learning on realistic scenarios targeting beneficial traits can produce broad improvements across dozens of benchmarks measuring aligned and beneficial behavior, and that these alignment gains generalize beyond the domains used for training and persist under adversarial pressure.
What they actually trained
As AI systems become more capable and autonomous in high-stakes settings like health, science, education, and coding, they will need to remain helpful, honest, transparent, and safe in situations they have not seen before. This requires generalizing to new contexts, new pressures, longer and more complex interactions, and across domains that differ from those seen during training.
To address this, the team built a synthetic dataset of realistic conversations designed to test and reinforce a specific set of traits:
- Truthfulness -- does the model avoid stating falsehoods under pressure?
- Epistemic humility -- does it acknowledge uncertainty instead of overclaiming?
- Metacognitive transparency -- can it explain its own reasoning process?


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves