
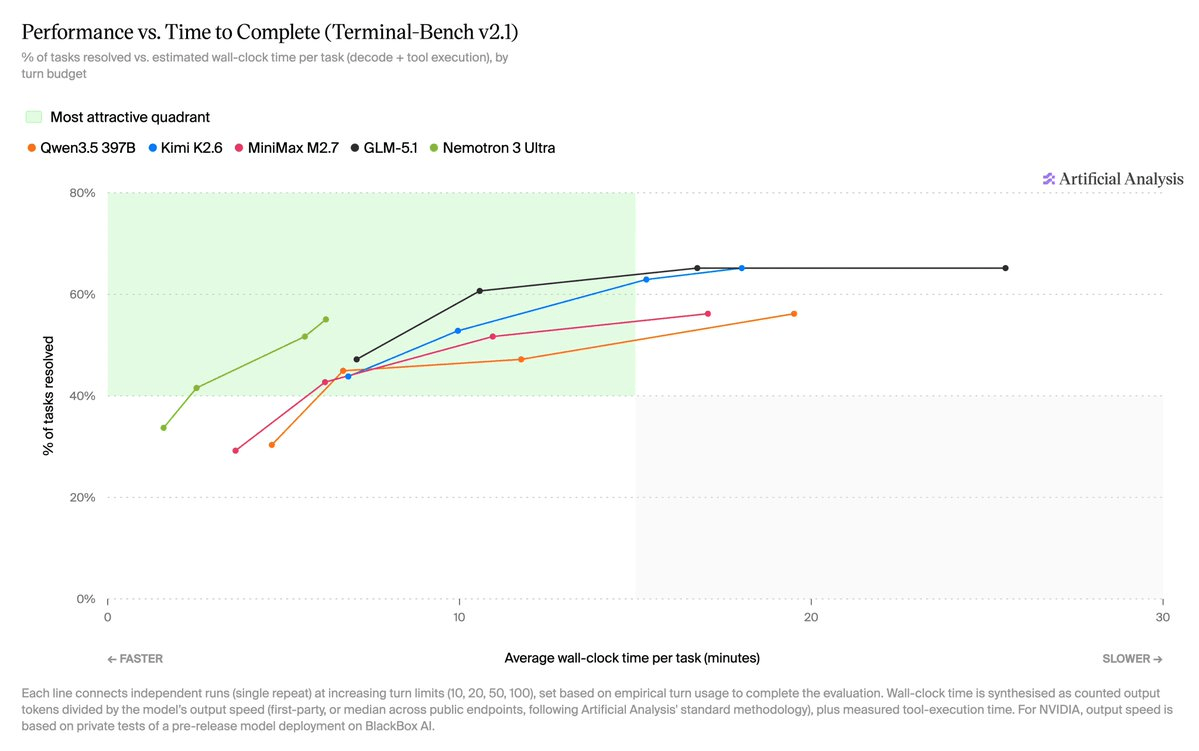
NVIDIA just shipped Nemotron 3 Ultra, a 550-billion-parameter open-weight reasoning model built from the ground up for long-running AI agents. It is now the most capable open model released by any US lab, scoring 47.7 on the Artificial Analysis Intelligence Index -- well ahead of the next best American open models, Gemma 4 31B (39.2) and gpt-oss-120b (33.3). The model is available today, weights and all, under the permissive OpenMDW-1.1 license from the Linux Foundation.
The headline number is not the benchmark score. It is the speed. Through BlackBox AI, Nemotron 3 Ultra is served at over 400 output tokens per second -- slightly faster than the typical serving speed of gpt-oss-120b despite being more than 4x larger, and with significantly greater intelligence. For agentic workloads where a model gets called thousands of times per workflow, that throughput gap changes the economics of the entire system.
Built for agents, not chatbots
The design goal here is explicit. NVIDIA did not build this to win single-turn chatbot comparisons. It built it to orchestrate agents that plan, call tools, delegate to sub-agents, read observations, and recover from errors across hundreds of turns, while burning fewer tokens than comparable open models. NVIDIA claims up to 5x higher throughput and up to 30% lower cost to complete agentic tasks than other open models in its class.
The model fits into a tiered system NVIDIA is pushing hard: Nano handles edge and high-volume execution, Super handles mid-tier workhorse tasks, and Ultra sits at the top as the frontier reasoning and orchestration layer. Because Ultra ships under a permissive license, its outputs can legally be used to post-train the smaller models below it -- something the terms of most closed frontier models prohibit.
Reasoning is also configurable. The model supports three modes: full thinking, medium effort, and reasoning off, all toggled through the chat template. You can also set a hard token ceiling on the thinking trace so the model stops deliberating once it hits the cap -- a practical control for agent builders watching token spend.
The architecture doing the heavy lifting
Nemotron 3 Ultra is NVIDIA's largest open model: 550B total parameters with up to 55B active per token via a hybrid Mamba-Transformer mixture-of-experts (MoE) architecture. That ratio -- 550B total, 55B active -- is the core of the efficiency story. It carries the knowledge capacity of a massive model while only paying the inference cost of a much smaller one.


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves