
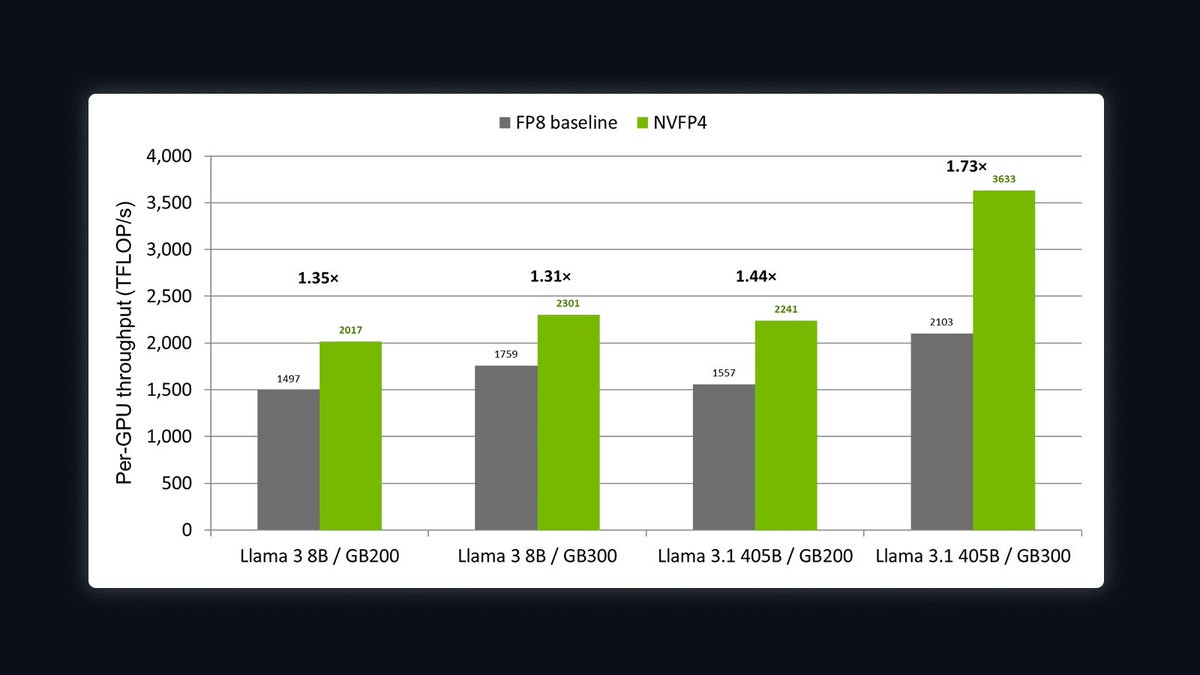
Pre-training a frontier LLM is a race against the clock. When training spans trillions of tokens across thousands of accelerators, every percentage point of step time can add up to days of training and substantial compute costs. NVIDIA just published a full recipe and benchmarks showing that switching from 8-bit (FP8) to 4-bit (NVFP4) precision during JAX-based pretraining delivers 1.31x to 1.73x faster throughput, with loss curves that are statistically indistinguishable from the FP8 baseline.
What just happened
NVIDIA released an end-to-end NVFP4 pretraining recipe for JAX, implemented in MaxText, NVIDIA's scalable LLM training library. The recipe is available now via the public ghcr.io/nvidia/jax:maxtext container, and it targets NVIDIA Blackwell hardware (GB200 and GB300). The benchmarks were run on Llama 3 8B and Llama 3.1 405B, covering both the GB200 Grace Blackwell Superchip and the newer GB300 Grace Blackwell Ultra Superchip.
The format itself: what is NVFP4?
NVFP4 is a purpose-built 4-bit floating point format developed for the Blackwell GPU architecture, aimed at improving efficiency of both training and inference tasks. The challenge with 4-bit representations is that you only have 16 unique values to work with, so a single outlier in a weight block can corrupt the entire quantization range. NVFP4 solves this with a two-level scaling strategy.
NVFP4 uses a two-level scaling trick: each value packs into an E2M1 format (1 sign bit + 2 exponent + 1 mantissa = 4 bits), groups of 16 values share one FP8 (E4M3) scale factor, and a single FP32 scale then applies across the whole tensor. This micro-scaling restores lost magnitude info that plain 4-bit formats discard, giving much better accuracy than standard FP4 or INT4 while staying very compact at roughly 4.5 bits effective per value.
This hardware-software co-design makes NVFP4 available only on Blackwell-based GPUs like the B300, B200, RTX Pro 6000/5000/4000, and RTX 5000 series. Previous architectures like Hopper or Ampere can emulate low-precision formats but lack dedicated datapaths, resulting in lower efficiency and higher effective latency. On the GB300, native hardware support of NVFP4 delivers 7x GEMM throughput compared to native FP8 precision on the NVIDIA Hopper.


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves