
Most AI benchmarks test a model's ability to answer a question. AA-Briefcase tests whether a model can hold down a job. Artificial Analysis just launched the benchmark, and it is one of the most demanding evaluations of real-world agentic capability published to date. NVIDIA was quick to highlight that its Nemotron 3 Ultra ranks among the top open-weight models on the new leaderboard.
What AA-Briefcase Actually Tests
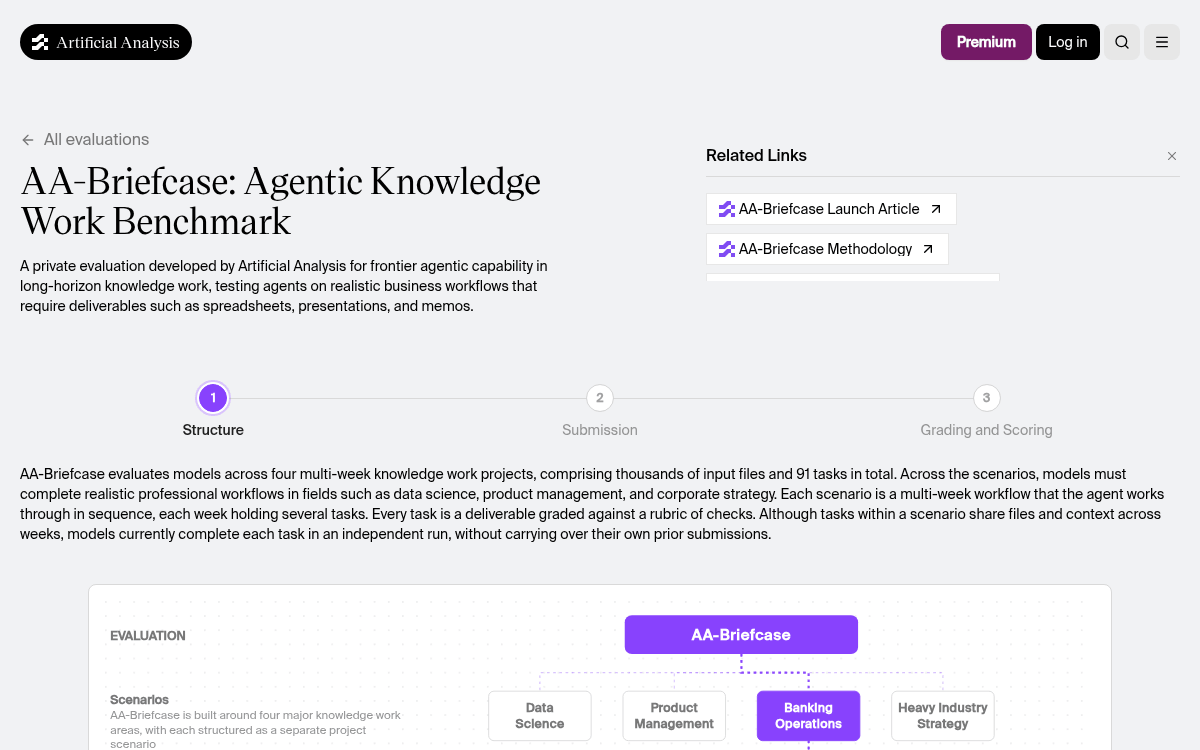
The benchmark is not a collection of isolated prompts. AA-Briefcase evaluates models across four multi-week knowledge work projects, comprising thousands of input files and 91 tasks in total. Across the scenarios, models must complete realistic professional workflows in fields such as data science, product management, and corporate strategy.
The four held-out scenarios cover:
- Data Science -- transaction data cleaning, forecast modeling, and schema design
- Product Management -- competitive teardowns, PRD writing, and go-to-market planning
- Banking Operations -- branch traffic analysis, financial modeling, and mortgage journey mapping
- Heavy Industry Strategy -- commodity price modeling, M&A comps, and government policy impact matrices
All four launch scenarios remain held out to reduce contamination risk and preserve AA-Briefcase as a reliable measure of frontier agent capability. A fifth public scenario called AA-Briefcase Lite is available on Hugging Face for anyone who wants to inspect the structure without influencing official scores.
What makes this benchmark unusually hard is the volume and messiness of the source material. AA-Briefcase is a private evaluation developed by Artificial Analysis for frontier agentic capability in long-horizon knowledge work, testing agents on realistic business workflows that require deliverables such as spreadsheets, presentations, and memos. The source material includes nearly 2,000 files, over 3,500 emails, and 25,000 Slack messages -- fragmented, contradictory, and realistic.
How the Scoring Works
AA-Briefcase Elo is a combined metric that aggregates rubric pass rate, analytical quality Elo, and presentation Elo. Rubric performance is converted into Elo via synthetic head-to-head matches. Think of it as a chess-style rating that combines three things: did the model get the facts right (rubric), was the analysis rigorous (analytical quality), and did the output look professional (presentation).


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves