
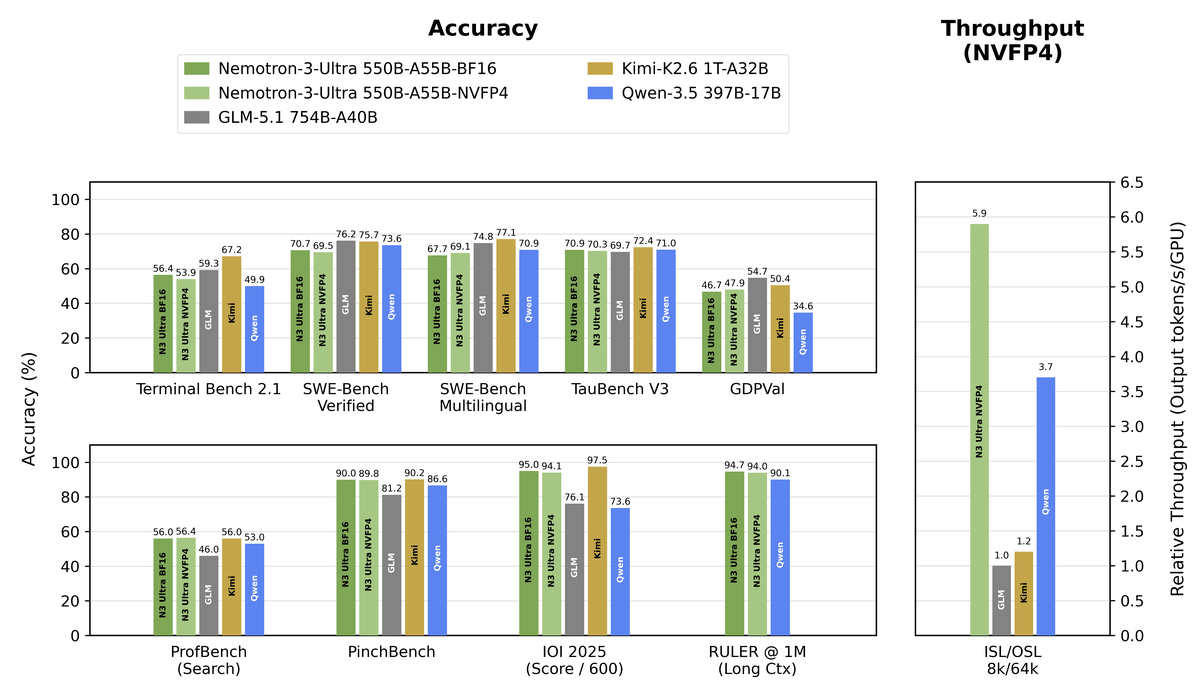
NVIDIA just dropped its biggest open model yet, and it's free to use right now. Nemotron 3 Ultra is a 550 billion total parameter model that activates only 55 billion of those parameters per token, and it's now available at no cost through OpenCode, the open-source terminal coding agent. The tweet that lit up the community was simple: "text · 1M context · fully open source." With 250k+ views, the response makes clear that the combination of scale, context length, and zero price tag hit a nerve.
This is not a minor model update. Nemotron 3 Ultra is the flagship of the Nemotron 3 family, announced at GTC San Jose 2026, and it represents NVIDIA's most serious push yet into the foundation model space. The architecture, training pipeline, and open release strategy all point to a deliberate attempt to challenge proprietary frontier models on their own turf.
A new kind of architecture under the hood
Nemotron 3 Ultra is NVIDIA's largest open model: 550B total parameters with up to 55B active per token via a hybrid Mamba-Transformer mixture-of-experts (MoE) architecture. The key word is hybrid. Nemotron 3 Ultra is not a standard transformer MoE. The architecture combines three components in a single hybrid stack: Mamba-2 SSM layers, MoE feed-forward layers, and standard attention layers.
Each of these three components does a different job. The MoE routing keeps compute low: the model has 550B total parameters across experts, but only 55B activate on any given forward pass. You need 550 GB of VRAM to hold all expert weights (at FP8), but the compute per token is equivalent to a 55B dense model. You pay for storage, not for compute. The Mamba-2 layers handle the long context: SSM layers maintain a recurrent state that scales linearly with sequence length rather than quadratically like attention. That linear scaling is what makes a 1M-token context window practical rather than theoretical.
Then there is LatentMoE, NVIDIA's proprietary twist on the standard MoE router. LatentMoE compresses tokens into a low-rank latent space before routing, enabling 4x as many expert specialists for the same inference cost. More experts for the same compute budget means more specialization without paying more at inference time. Finally, Multi-Token Prediction (MTP) predicts multiple future tokens in a single forward pass, improving chain-of-thought coherence and enabling built-in speculative decoding at inference time -- no separate draft model required.


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves