
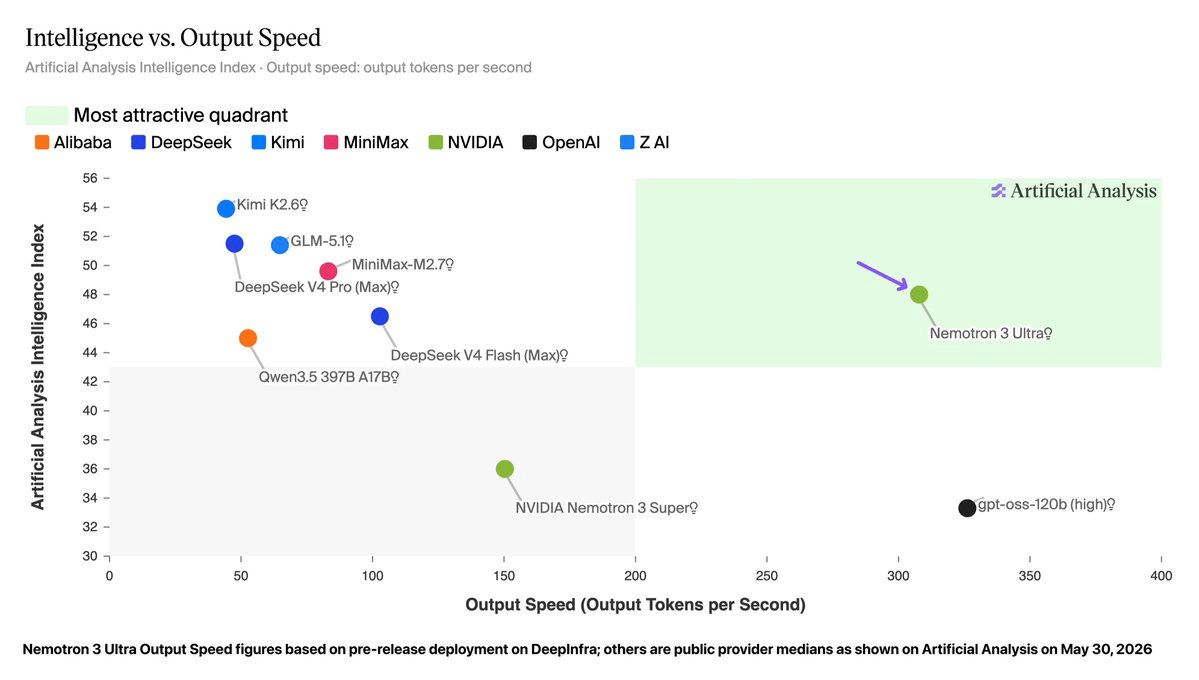
NVIDIA just shipped its biggest open model yet. Nemotron 3 Ultra is a 550 billion parameter Mixture-of-Experts reasoning model, announced at Jensen Huang's Computex keynote and released days later with full weights, training data, and recipes under a permissive Linux Foundation license. The headline benchmark number is 48 on the Artificial Analysis Intelligence Index, making it the most capable open-weights model to come out of a US lab. But the more interesting story is why it was built, and what it trades to get there.
Not a chatbot. An orchestrator.
Nemotron 3 Ultra targets a specific problem: long-running agents that plan, call tools, and reason across many turns. As agents run longer, token counts grow and inference cost climbs. Ultra is designed to keep accuracy high while making that inference faster and cheaper. NVIDIA's framing is explicit: this model is not competing on single-turn chat quality. It is competing on cost per completed agentic task.
What makes Nemotron 3 Ultra different is the design goal. NVIDIA did not build this to win single-turn chatbot comparisons. According to the NVIDIA blog, it built it to orchestrate agents that plan, call tools, delegate to sub-agents, read observations, and recover from errors across hundreds of turns, while burning fewer tokens than comparable open models.
The Nemotron 3 family is tiered by design. Nano handles edge and on-device workloads. Super handles high-volume execution. Ultra sits at the top as the reasoning orchestrator, and because all three are open under the same permissive license, Ultra's outputs can legally be used to post-train the smaller models below it , something the terms of most closed frontier APIs prohibit.
The architecture is the bet
Nemotron 3 Ultra is a 55B active, 550B total parameter Mixture-of-Experts hybrid Mamba-Transformer model that leverages LatentMoE, includes MTP layers, and was pre-trained in NVFP4. Each of those pieces is doing real work.
- Hybrid Mamba-Transformer: Nemotron 3 Ultra employs a Mixture-of-Experts hybrid Mamba-Attention architecture, leading to improvements along the inference-throughput-to-accuracy frontier. While Mixture-of-Experts help Ultra achieve better accuracy per active parameter, the hybrid Mamba-Attention architecture significantly improves inference throughput by reducing attention cost and KV cache footprint.


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves