
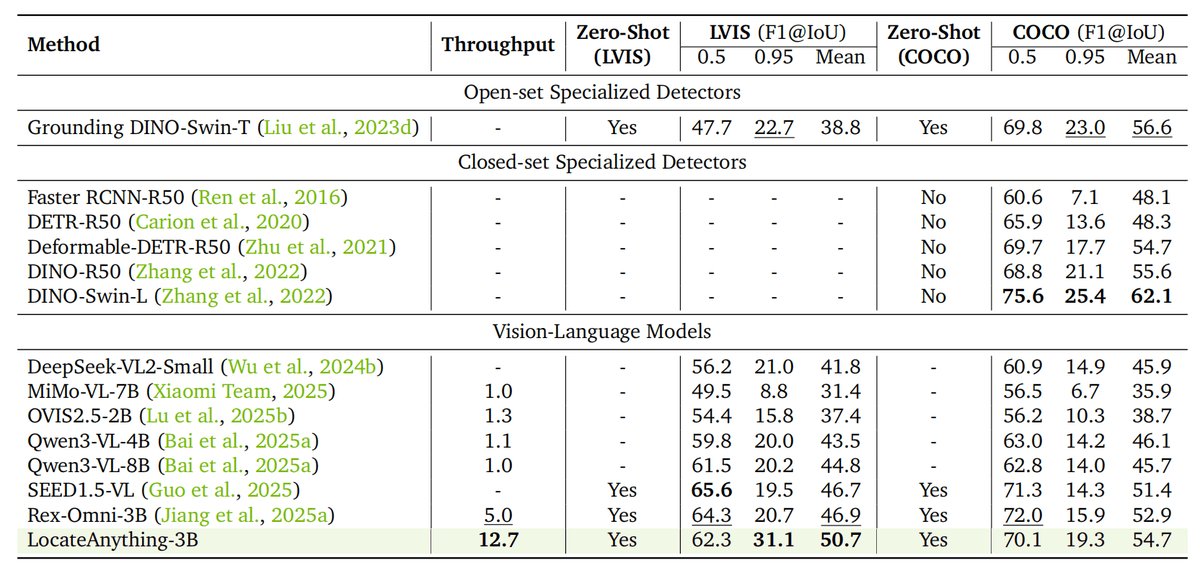
Most vision-language models treat object detection as a writing exercise. They serialize a bounding box into a string of coordinate tokens -- x1, then y1, then x2, then y2 -- and generate them one at a time, the same way a language model writes a sentence. It works, but it is slow and geometrically naive: the model has no built-in understanding that those four numbers belong together as a rectangle. LocateAnything, a CVPR 2026 paper from NVIDIA Research, fixes this with a fundamentally different approach that hit #1 trending on Hugging Face the day it dropped.
The bottleneck nobody talks about
When you deploy a vision-language model for detection in a real system -- a robot arm, a GUI agent, an autonomous vehicle -- the bottleneck is rarely the vision encoder. It is the autoregressive decoder grinding out coordinate tokens sequentially. VLMs commonly formulate visual grounding and detection as a coordinate-token generation problem, serializing each 2D box into multiple 1D tokens that are learned and decoded largely independently. This creates two compounding problems: token-by-token decoding mismatches the coupled structure of box geometry and creates a practical inference bottleneck due to strictly sequential generation.
The geometry problem is subtle but important. When a model predicts x1 without knowing x2 yet, it has no way to enforce that the resulting box makes spatial sense. Coordinates end up inconsistent, especially in dense scenes where objects overlap. Prior work tried quantizing coordinates into discrete bins ("quantized coordinate decoding") to speed things up, but this only partially addresses the sequential bottleneck and introduces its own accuracy tradeoffs.
Boxes as atomic units
LocateAnything's core innovation, Parallel Box Decoding (PBD), predicts complete bounding box coordinates in a single parallel step rather than autoregressive token-by-token decoding, improving efficiency while preserving geometric consistency. Think of it like the difference between writing a sentence word-by-word versus stamping the whole word at once. Each box -- all four coordinates together -- is treated as one indivisible prediction unit.


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves