
Tuning an LLM serving stack is one of those problems that looks manageable until you actually try it. You have to pick a model backend, a tensor-parallel shape (how many GPUs share the model), whether to split prefill and decode across separate workers, how many workers to run, how the router assigns requests, how the KV cache behaves across memory tiers, and when the autoscaler should fire. Every one of those choices interacts with the others, and a tweak that improves throughput can silently blow up latency somewhere else. For large models, even a single realistic experiment can burn through many GPU-hours before you learn whether the idea was worth testing.
NVIDIA's answer to this is DynoSim: a full-stack simulator for the Dynamo inference serving framework that lets you screen thousands of deployment configurations in software before touching real hardware.
The GPU tax on deployment search
Inference engines optimize the GPU itself, while Dynamo adds the distributed layer on top: disaggregated serving, smart routing, KV cache management across memory tiers, and auto-scaling. That distributed layer is where the hard tuning lives, and it is expensive to explore empirically. DynoSim is a workload-driven discrete-event simulation of the Dynamo serving stack that combines measured engine forward-pass timing, scheduler behavior, Router and Planner logic, KV cache effects, and workload traces on one virtual timeline.
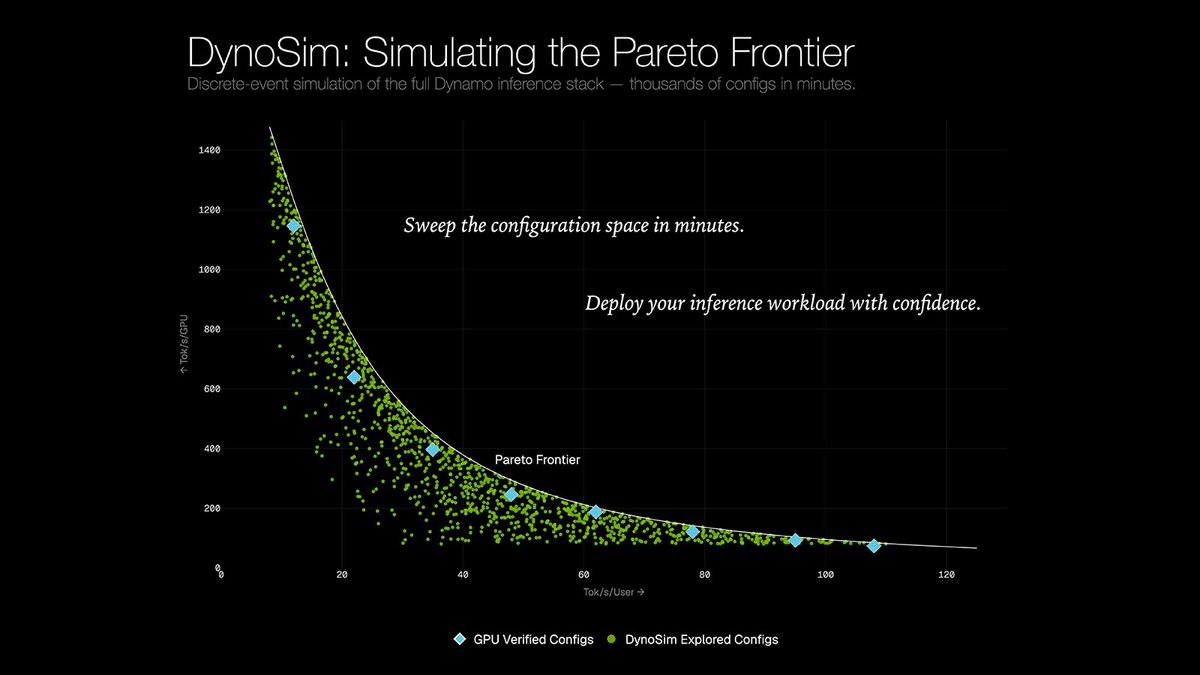
The core idea is a simulate-then-verify loop. Instead of running every candidate configuration on a real cluster, teams sweep thousands of options in simulation, shortlist the Pareto-optimal candidates (the configs that offer the best tradeoff between latency and throughput), and only then validate those few on real GPUs. The recommended workflow goes from a single DynoSim run to verify workload shape, then DynoSim sweeps to search the design space, then live Mocker deployments to exercise the real Dynamo frontend without running model inference, and finally real-GPU validation before production rollout.
1,500x faster than real time, on a laptop
The speed claim is the headline number, and it holds up. DynoSim is a full-stack Rust implementation. On an Apple M4 MacBook Air, the single-threaded offline replay simulated the full 23,608-request Mooncake trace with eight round-robin workers in 2.41 seconds of wall time, covering a simulated serving window of 60.1 minutes, about 1,500x faster than real time. That means a sweep over thousands of configurations that would take weeks of GPU time can run in minutes on a developer's laptop.


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves