
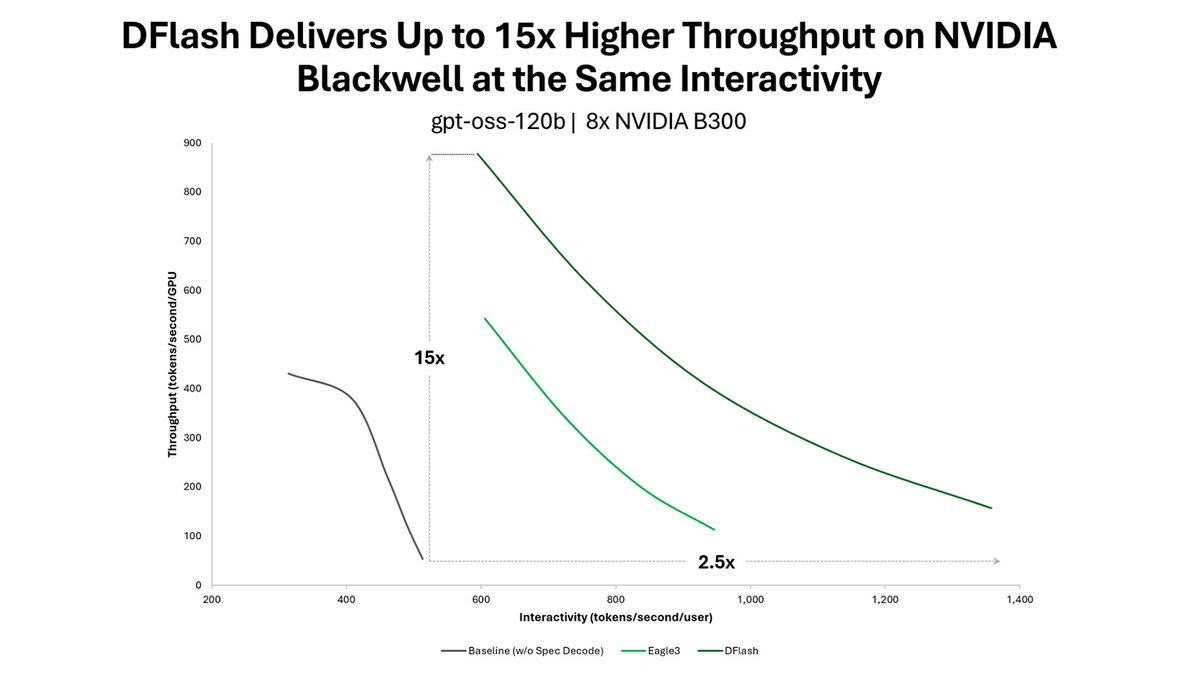
NVIDIA has published a full technical endorsement of DFlash, a speculative decoding technique that can push LLM inference throughput up to 15x higher on Blackwell hardware. More importantly, NVIDIA's inference engineering teams have done the integration work to bring DFlash into SGLang, vLLM, and TensorRT-LLM, meaning you can drop it into your existing serving stack without touching your application code.
The problem with how speculative decoding works today
Speculative decoding is a well-established trick for accelerating LLM inference. A small, fast draft model proposes several tokens ahead, and the large target model verifies them all in one parallel pass. If the draft was right, you get multiple tokens for the cost of one verification step.
The catch is that most draft models, including the popular EAGLE series, still generate their proposals autoregressively -- one token at a time. That means the drafting step itself is sequential, which caps how much parallelism you can actually extract. Methods like EAGLE and the native multi-token prediction modules in Gemma 4 and DeepSeek still rely on sequential autoregression in the draft model, generating tokens one-by-one -- a poor fit for modern hardware and a hard limit on achievable speedup.
What DFlash does differently
DFlash is an open source lightweight block diffusion model designed for speculative decoding. Its drafter generates an entire block of candidate tokens in a single forward pass, turning sequential drafting into block-parallel GPU work while preserving the target model's output quality through verification.
The architecture has three key components working together:
- Block-diffusion drafting: Instead of predicting the next token, the draft model predicts a whole block of masked future tokens simultaneously in one forward pass.
- Target hidden-state conditioning: DFlash utilizes the target model's hidden features as context, conditioning the draft model to predict future blocks of tokens in parallel. Large autoregressive LLMs implicitly encode information about multiple future tokens in their internal representations.


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves