
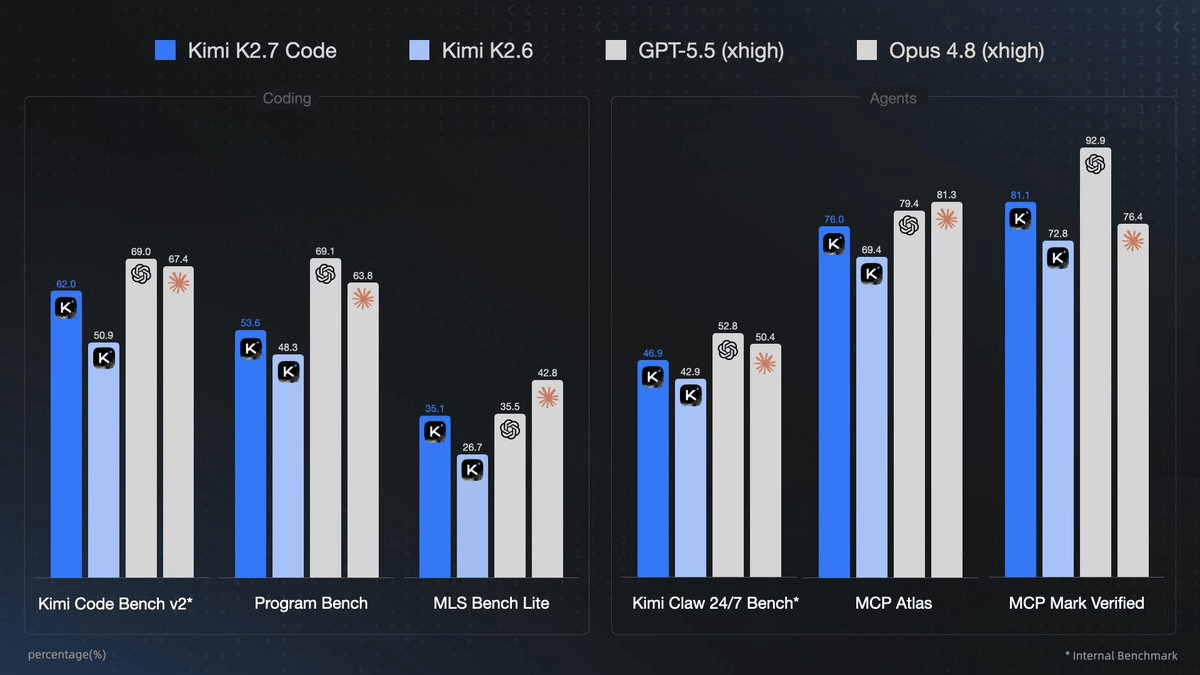
Moonshot AI just shipped Kimi-K2.7-Code, a coding-specialized update to its K2 model family, and open-sourced the weights on the same day. The headline numbers are hard to ignore: +21.8% on Kimi Code Bench v2, +11.0% on Program Bench, and +31.5% on MLS Bench Lite versus K2.6. But the more interesting story is what the model does less of: it uses 30% fewer reasoning tokens to get there.
The overthinking problem, solved
Reasoning models have a well-known failure mode: they burn enormous amounts of compute spinning through unnecessary thinking steps before producing an answer. Ethan Mollick's Lem Test had K2.6 generating a 74-page thinking trace to produce an okay-ish answer, and Artificial Analysis measured K2.6 burning roughly 160M reasoning tokens to run their Intelligence Index, versus ~110M for GPT-5.4. K2.7-Code directly attacks this. Reasoning efficiency is one of its headline claims: less overthinking, with 30% lower reasoning-token usage compared to K2.6. In practice, this means faster completions and lower API costs on reasoning-heavy coding tasks.
This matters because per-token cheap doesn't equal per-task cheap. On reasoning-heavy workloads, headline savings can compress significantly, and the real number has to be calculated against actual workflow shape, not the rate card. A model that reasons more efficiently is a model that's actually cheaper to run in production.
What's under the hood
K2.7-Code sits on top of the same 1-trillion-parameter Mixture-of-Experts (MoE) architecture that has defined the K2 family since the beginning. MoE means the model has a huge total parameter count but only activates a fraction of them per token during inference. The architecture uses 32 billion active parameters per token, with 384 experts per layer (8 routed plus 1 shared), Multi-head Latent Attention to compress the KV cache, SwiGLU activation, and native INT4 quantization. Inference cost stays at the 32B level while model capacity is 1T.


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves