
Flash Attention is one of the most celebrated optimizations in modern deep learning , but it was designed for the general case. TLX Block Attention, a new open-source kernel from Meta's Ads AI team, asks a sharper question: what if you already know your attention pattern at compile time? The answer, it turns out, is a 2.3x speedup over Flash Attention v2 and a 3.5x speedup when rotary embeddings are fused into the backward pass.
The Pattern That Changes Everything
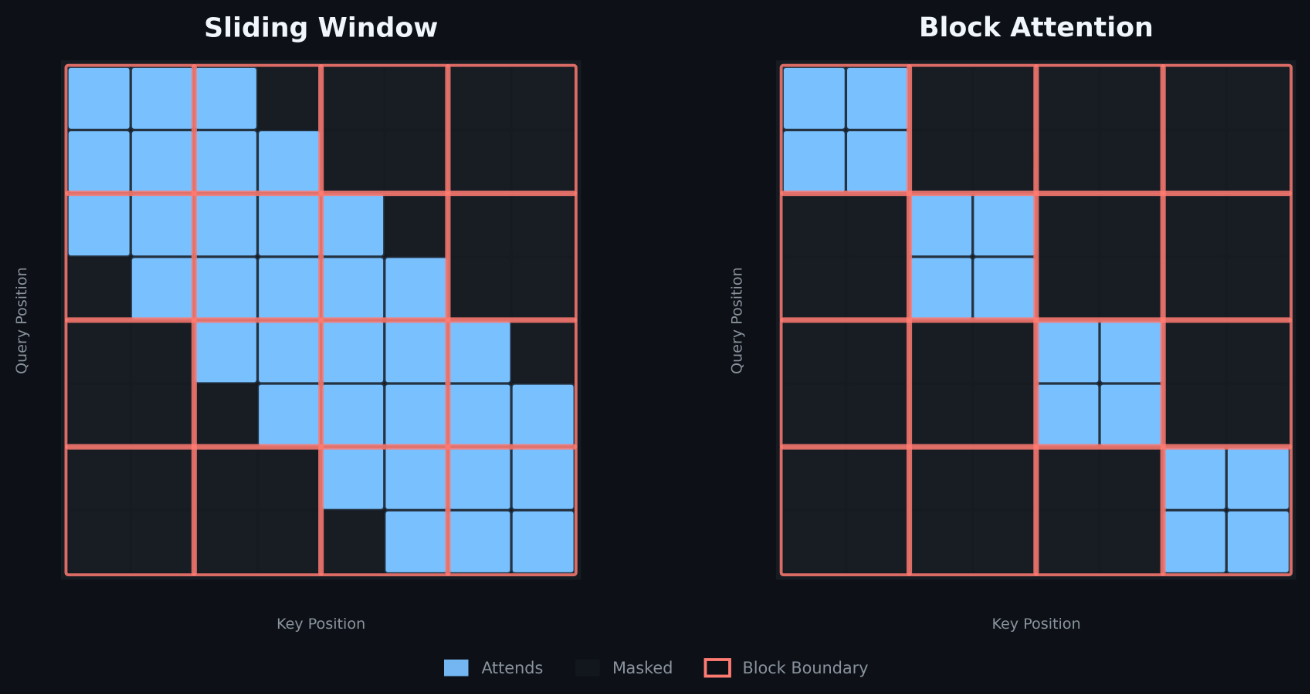
Block-diagonal self-attention is a specific structural pattern where a sequence is split into fixed-size groups, and each token only attends to others within its own group. It sounds like a constraint, but it's actually a very common design in recommendation and feature-interaction models , the kind that power ads ranking systems at scale. Meta's production workloads run batch sizes of 1152, sequences up to ~4k tokens, and roughly 70% sparsity in the attention structure.
The problem is that general-purpose kernels like Flash Attention v2 don't know about this structure ahead of time. They're built to handle arbitrary-length causal attention, which means they carry a lot of algorithmic machinery that becomes pure overhead when the pattern is fixed. FlexAttention (FA4) supports block-sparse patterns but has a minimum tile size of 256 , incompatible with the 64-token blocks these models require.
One Constraint, Five Eliminations
The core insight is deceptively simple: in block-diagonal attention, every query (Q) tile attends to exactly one key/value (K/V) tile , its own block. That single constraint cascades through the entire Flash Attention algorithm and eliminates five categories of overhead:
- No multi-tile loop. The score matrix S = Q·Kᵀ is complete after a single matrix multiply. There is no iteration to maintain state across.
- No online softmax correction. Standard Flash Attention applies a correction factor at each tile step to stay numerically stable. With one tile, the row-wise max and sum are globally correct immediately , the correction factor is identically 1 and can be dropped.
- No logsumexp (L) tensor. Flash Attention saves a per-row log-sum-exp tensor to GPU memory (HBM) so the backward pass can reconstruct attention probabilities. With a single tile, the backward pass can recompute everything inline , eliminating an entire HBM write and read per forward/backward pair.


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves