
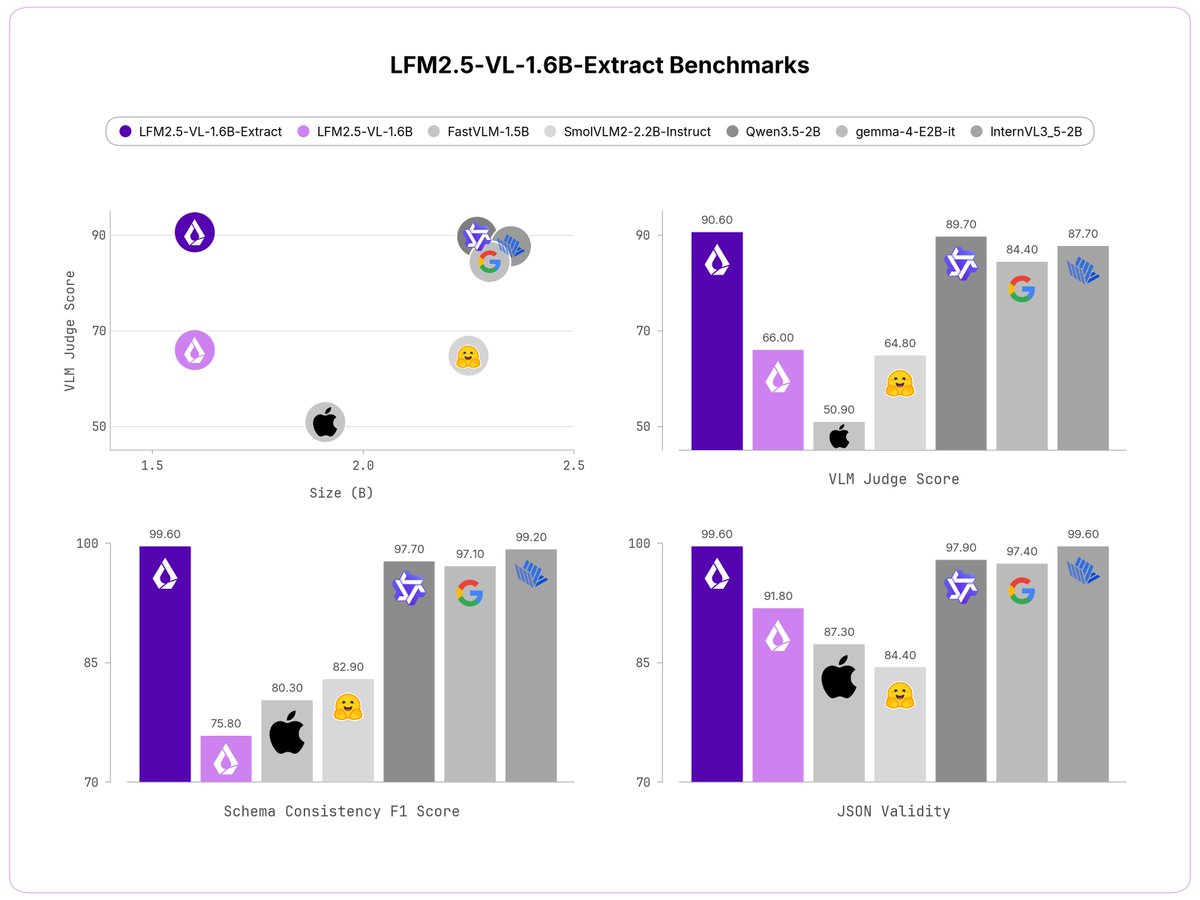
Liquid AI just dropped two task-specific vision-language models that skip the usual ritual of coaxing structured data out of free-form text. LFM2.5-VL-1.6B-Extract and LFM2.5-VL-450M-Extract take an image plus a YAML list of fields and return a populated JSON object directly. No regex, no Pydantic retries, no second pass through a language model to clean things up.
Both models are open-weight under the LFM Open License v1.0, available now on Hugging Face, and small enough to run on a phone or an embedded SoC.
The parsing layer disappears
The usual pipeline for pulling structured data out of an image looks like: VLM describes the scene, you prompt it to format as JSON, you parse, you handle failures, you retry. The Extract models collapse that into a single call. You specify what to extract as a YAML field list in the system prompt, and the model returns a JSON object with those fields.
The schema itself doubles as documentation for the model. Each field gets a short natural-language description, and there is an enum mode where you list allowed values and the model picks one:
wood_color: The overall coloration of the wood surface, such as blue, red, or light tan
wood_texture: The tactile quality of the wood surface, select from smooth, rough, or grainy
wood_pattern: The pattern types visible on the wood surface, e.g., straight, wavy, or curly

Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves