
Liquid AI just shipped LFM2.5-8B-A1B, a Mixture-of-Experts model purpose-built to run a complete agentic loop , tool calling, reasoning, and multi-step instruction following , entirely on consumer hardware. No cloud. No API keys. No data leaving the machine. The weights are available now on Hugging Face, and the model is free to use under Liquid's open-weight LFM license.
The number that matters isn't 8B
The model holds 8.3B total parameters but activates only 1.5B per token , that sparsity is what lets it run on consumer hardware. This is the core design bet: a Mixture-of-Experts (MoE) architecture routes each token through only a fraction of the network, keeping compute and memory usage low while preserving the capacity of a much larger model. In Liquid's framing, only 1.5B parameters are active during inference, which changes the budget line from "how big is the model" to "how much of the model wakes up."
Unlike its predecessor, LFM2.5-8B-A1B is a reasoning-only model, producing an explicit chain of thought before its final answer. Liquid adopted this strategy because MoE models generally run in compute-bound settings, where a smaller number of active parameters makes each reasoning token cheap , providing a significant quality boost without compromising speed.
A step change from the previous generation
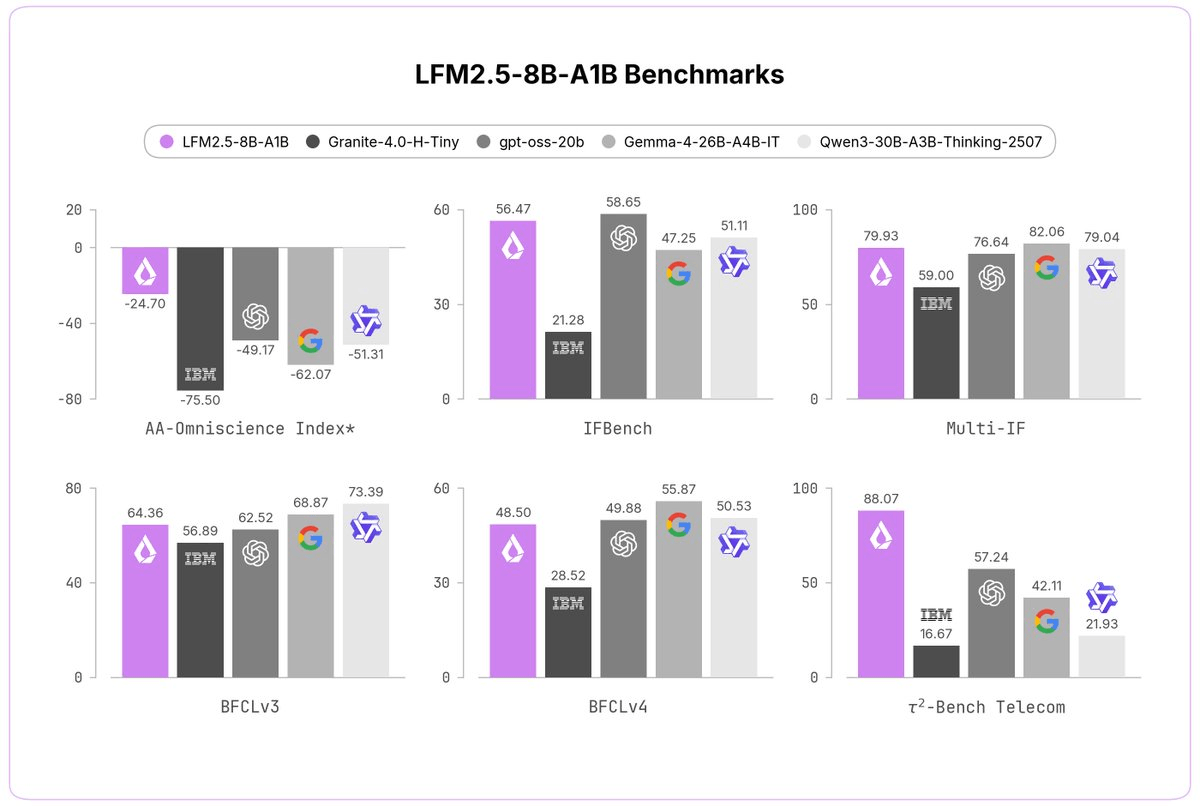
LFM2.5-8B-A1B builds on LFM2-8B-A1B from October 2025, with an expanded 128K context window, scaled-up pretraining from 12T to 38T tokens, and large-scale reinforcement learning. The benchmark improvements are dramatic across the board:
- A 53.62-point increase on the AA-Omniscience Index and a 56.01-point rise in the non-hallucination rate.
- IFEval (instruction following) rose from 79.44 to 91.84.
- MATH500 climbed from 74.80 to 88.76.
- Tau² Telecom (agentic tool-use benchmark) rose from 13.60 to 88.07.
- IFBench jumped from 26.00 to 56.47 , more than doubling.
The avg@k-based reward , a reinforcement learning technique that scores a model by averaging performance across multiple sampled outputs , enables LFM2.5-8B-A1B to achieve a significantly lower hallucination rate while maintaining reasonable accuracy. It also leads on instruction following benchmarks, matching bigger MoEs like Gemma 4-26B at a fraction of the active parameter count.


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves