
Retrieval is one of those problems where you're always trading something. Speed costs accuracy. Accuracy costs index size. Multilingual coverage costs both. Liquid AI just released two models that try to sidestep that tradeoff: LFM2.5-Embedding-350M and LFM2.5-ColBERT-350M, a pair of 350M-parameter multilingual retrieval models that cover 11 languages and hit sub-2ms query latency on GPU.
Two models, one decision
Both models are 350M parameters and the first bidirectional members of the LFM family, built on LFM2.5-350M-Base. They are designed for fast and reliable multilingual and cross-lingual search across 11 languages, with a footprint small enough to run almost anywhere.
The two models represent different points on the speed-vs-accuracy curve:
- LFM2.5-Embedding-350M: turns each document into a single vector. Pick it when you want the fastest search and the smallest, cheapest index.
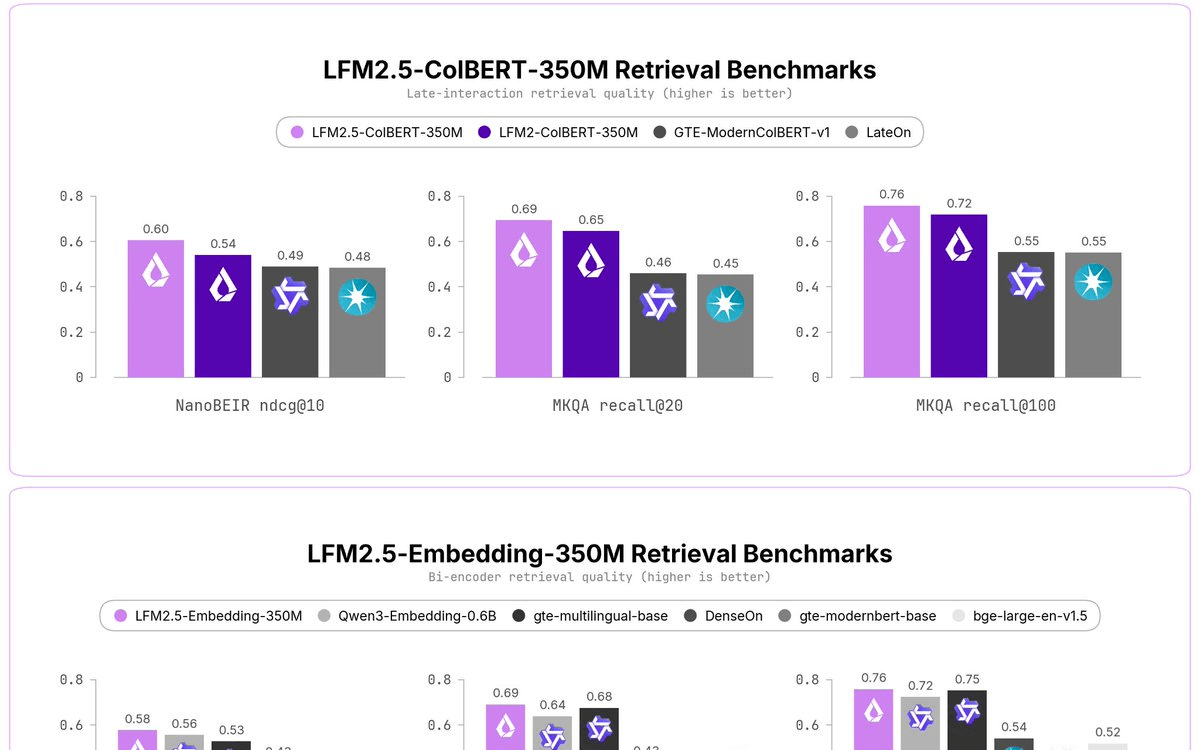
- LFM2.5-ColBERT-350M: converts each token into a vector rather than a single vector per document. This lets it match queries word-by-word for higher accuracy and better generalization, at the cost of a larger index. Pick it when accuracy matters more than storage.
The ColBERT approach (late interaction) is worth understanding. Queries and documents are encoded separately at the token level. The system compares token vectors at query time using MaxSim (maximum similarity). This preserves fine-grained token interactions without the full cost of joint cross-attention, and allows pre-computation for documents. In practice, you get something closer to a reranker's precision at a bi-encoder's speed.
The architecture trick that makes it work
Both models are built from LFM2.5-350M-Base, a mid-trained general-purpose checkpoint. Liquid AI applies a small set of bidirectional patches to the LFM2 architecture, adapting it from a causal decoder to a bidirectional encoder.
This is the key architectural move. Standard LFMs are causal: each token only sees what came before it, which is great for text generation but suboptimal for retrieval. The team replaces the causal attention mask with a bidirectional one, so every token can attend to both left and right context. They also make the LFM2 short convolutions non-causal, so they mix local information symmetrically around each token rather than only from the past.


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves