
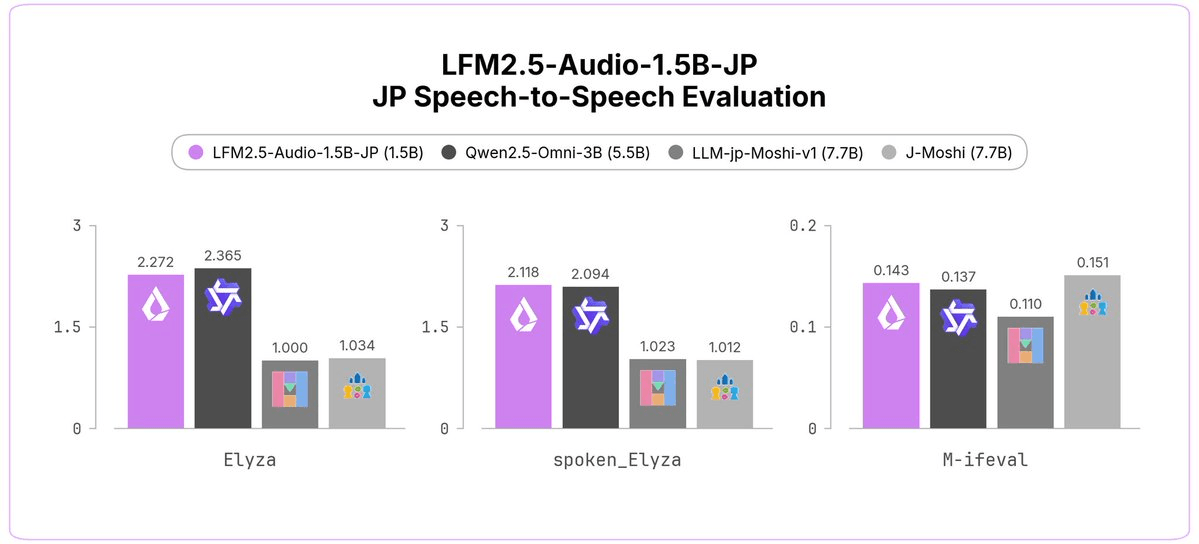
Liquid AI just dropped two new Japanese-language models, and the headline number is hard to ignore: a 1.5B-parameter audio model that outperforms a 7.7B-parameter competitor on conversational Japanese benchmarks. The release covers two distinct models , LFM2.5-Audio-1.5B-JP, an end-to-end speech model, and LFM2.5-1.2B-JP-202606, an updated general-purpose Japanese chat model , both available now on Hugging Face.
One Model to Rule ASR, TTS, and Chat
The audio model is the more novel of the two. Most Japanese voice pipelines today are assembled from separate components: an ASR model to transcribe speech, a language model to generate a response, and a TTS model to speak it back. LFM2.5-Audio-1.5B-JP is an end-to-end multimodal speech and text language model that does not require separate ASR and TTS components. You speak in, it speaks back , one model, one forward pass.
Designed with low latency and real-time conversation in mind, at only 1.5 billion parameters LFM2.5-Audio-JP enables seamless Japanese conversational interaction, achieving capabilities on par with much larger models. That last part is the key claim: the model punches well above its weight class.
The Architecture Under the Hood
The model consists of a pretrained LFM2.5 model as its multimodal backbone, along with a FastConformer-based audio encoder to handle continuous audio inputs, and an RQ-transformer generating discrete tokens coupled with a lightweight audio detokenizer for audio output. FastConformer is a convolution-augmented transformer architecture originally developed by NVIDIA for efficient speech encoding. The RQ-transformer (Residual Quantization transformer) handles converting the language model's outputs into discrete audio codes, which are then decoded into a waveform.


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves