
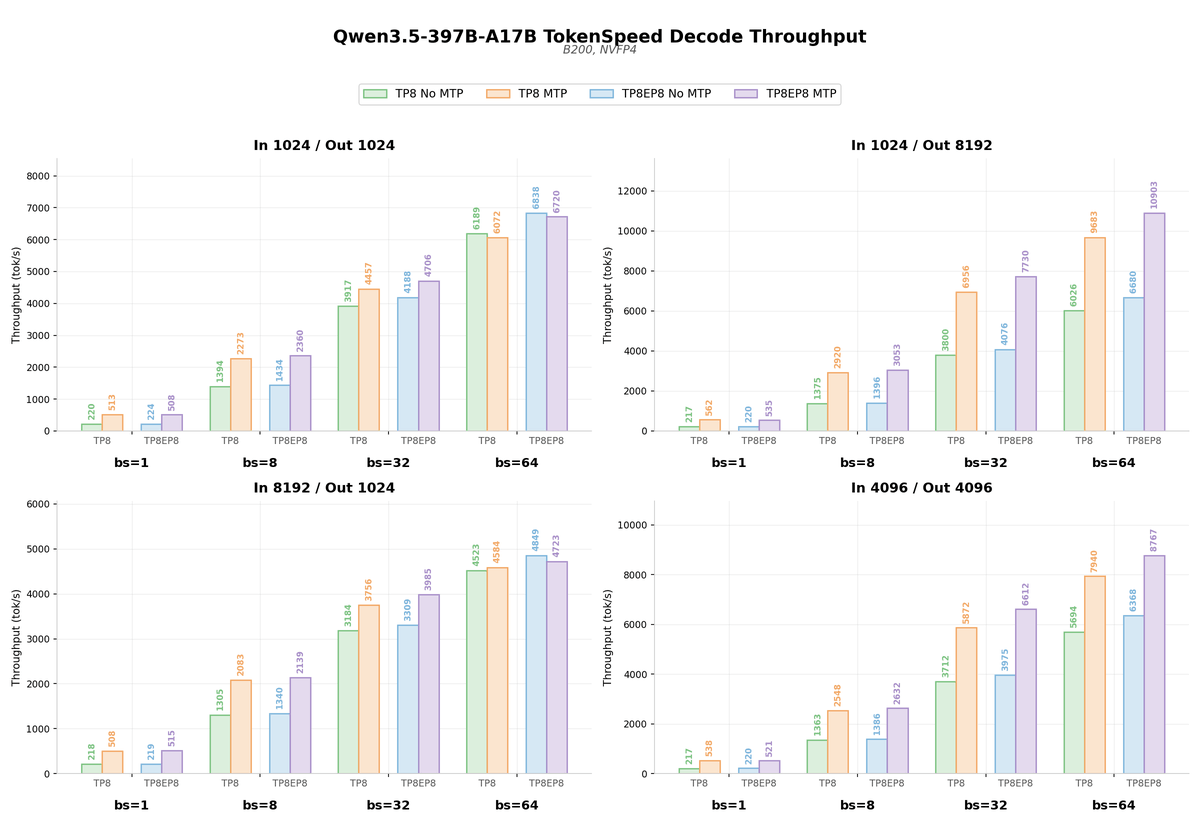
TokenSpeed, the open-source inference engine from the LightSeek Foundation, just set a new throughput record: 580 tokens per second on Alibaba's Qwen3.5-397B-A17B model, running on NVIDIA Blackwell GPUs. That's 580 tokens per second from a nearly 400-billion-parameter model -- a number that would have seemed implausible even a year ago. The result is a joint effort between the Qwen inference team, the LightSeek Foundation, NVIDIA, and the Mooncake team, with special contributions from Tri Dao on FlashAttention-4 (FA4).
Why Qwen3.5 is hard to serve fast
Before getting into the engine, it helps to understand what makes Qwen3.5 unusual. Qwen3.5 adopts a hybrid attention mechanism that interleaves standard full attention layers with linear attention layers based on the Gated Delta Network (GDN). Unlike traditional pure-Transformer architectures, this hybrid design maintains strong modeling capabilities while significantly reducing computational complexity for long-sequence inference.
GDN (Gated Delta Network) is essentially a smarter form of linear attention. Instead of maintaining an ever-growing attention map, each GDN layer keeps a fixed-size state matrix with dimensions proportional to the head dimension squared, independent of sequence length. New tokens update this state incrementally, and the output for each token is produced by querying the current state. The cost becomes O(n * d^2): linear in sequence length, quadratic only in the small, fixed head dimension. The model alternates between Gated DeltaNet layers (linear attention) and full attention layers in roughly a 3:1 ratio.
The catch: GDN layers carry a persistent recurrent state (like Mamba) that must be tracked, cached, and transferred alongside the conventional KV cache. That's a fundamentally harder serving problem than a standard Transformer, and it's where most inference engines fall short.
The engine built for agents, not chatbots
TokenSpeed is a speed-of-light LLM inference engine developed by the LightSeek Foundation, released as open source under the MIT license. The project targets agentic workloads and aims to deliver TensorRT-LLM-level performance with vLLM-level usability, combining a C++ control plane with a Python execution layer to keep CPU-side overhead minimal while preserving developer ergonomics.
Coding agents present unusually demanding inference workloads. Contexts routinely exceed 50K tokens, and conversations often span dozens of turns. Most public benchmarks do not fully capture this behavior. Because generation speed is crucial to the user experience for agents, the objective is to maximize per-GPU TPM (tokens per minute) while maintaining a per-user TPS floor -- typically 70 TPS, and sometimes 200 TPS or higher.


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves