

DeepSeek just made its V4 models 60% to 85% faster per user, without retraining a single model weight.
The method is called DSpark, and it shipped open source under an MIT license.
Its real move is not a faster draft model. It is deciding which guesses are even worth checking.
Context
The research comes from DeepSeek-AI and Peking University, in a paper titled "DSpark: Confidence-Scheduled Speculative Decoding with Semi-Autoregressive Generation." It landed alongside DeepSpec, an MIT-licensed repo for training and evaluating draft models.
Most people saw it through a post by Daniel Han of Unsloth, not an official DeepSeek account.
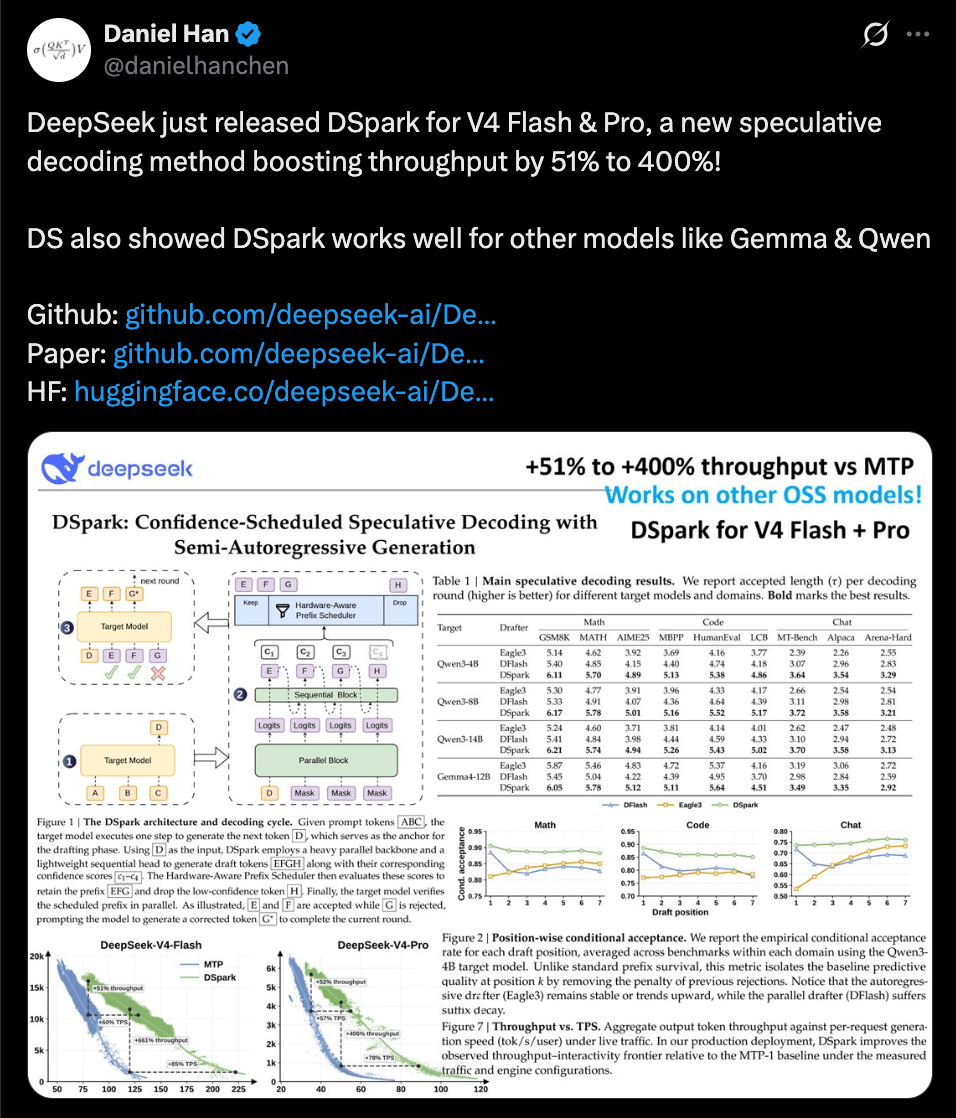
A quick refresher on what it speeds up. Speculative decoding is the standard way to make generation faster without changing the output.
A small draft model guesses several tokens ahead, the full model checks the whole guess in one pass, and it keeps the longest run that matches. Because the check uses rejection sampling, the final text is identical to what the big model would have written alone.
The core idea in plain English

There are two ways to build the draft model, and each has a flaw. Parallel drafters write the whole guess in one shot, which is fast, but the later words drift because each position is picked without seeing the ones chosen before it.
The textbook failure is blending two valid phrases like "of course" and "no problem" into "of problem." Autoregressive drafters avoid that by writing one word at a time, but writing word by word is slow.
DSpark keeps the fast parallel draft and adds a tiny corrector on top that nudges each word based on the one just picked. Then it adds a second small model that scores how likely each guessed word is to pass the full model's check.
A scheduler reads those scores and the current GPU load, and sends only the worthwhile guesses for verification. When the GPUs are busy, it stops checking guesses that probably will not survive.
Draft better, verify smarter
DSpark improves two of the three levers that set speculative-decoding speed. Per-token latency is the draft time plus the verify time, divided by how many tokens get accepted per round.
You can draft faster, accept more, or verify cheaper. DSpark does the last two.

Draft better: a parallel backbone with a sequential head.
The heavy work stays in a parallel backbone, the same DFlash design that produces a full block of guesses in one forward pass. On top sits a lightweight Markov head that adjusts each word's odds using only the word right before it.
It is stored as a small rank-256 factorization, so it adds almost no cost.
Adding it raises round latency by 0.2% to 1.3% at batch size 128, and in return the model accepts up to 30% more tokens. A two-layer DSpark beats a five-layer DFlash, so the correction earns more than extra depth would.


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves