
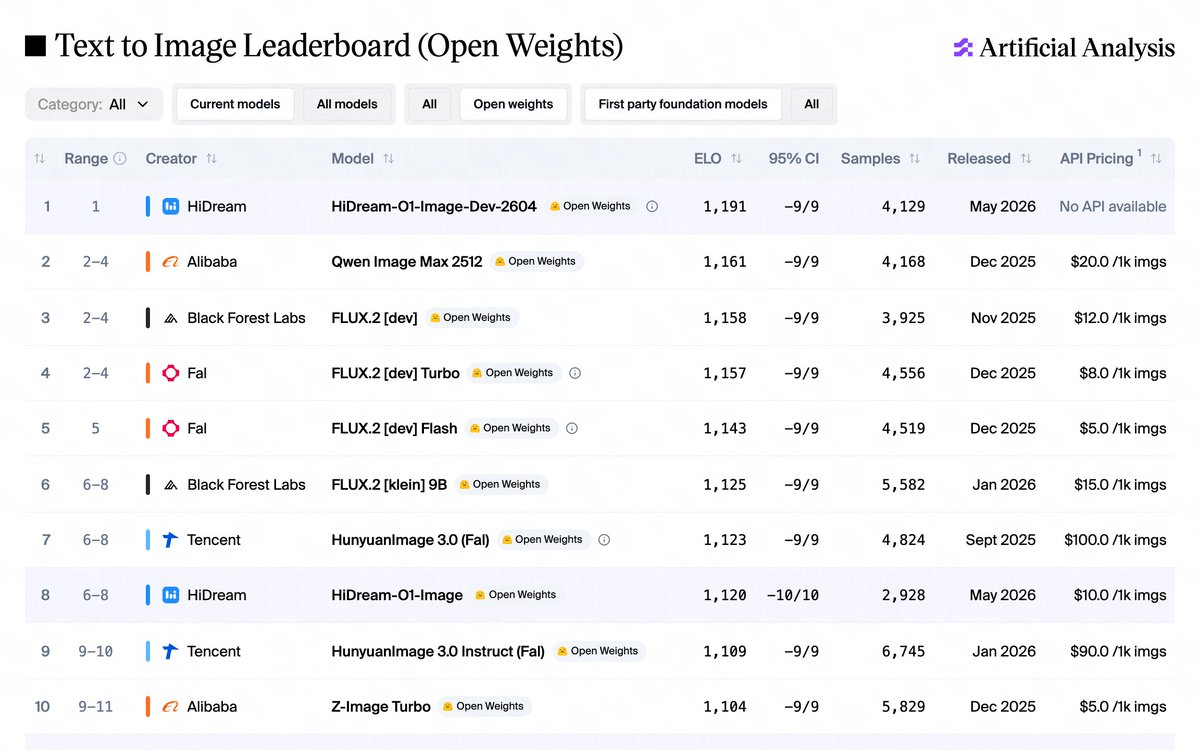
HiDream-O1-Image is not a marginal improvement on the existing image generation stack. It throws out the stack. Where virtually every modern text-to-image model compresses pixels into a latent space using a Variational Autoencoder (VAE) before doing anything useful, HiDream-O1 skips that step entirely and runs diffusion directly on raw pixels. The result is an 8B-parameter model that, on multiple standard benchmarks, beats models carrying 7x more parameters, and does it under an MIT license that allows unrestricted commercial use.
One checkpoint, three jobs
HiDream-O1-Image breaks from the conventional diffusion pipeline by eliminating external VAEs and separate text encoders, instead working directly in raw pixel space through an entirely new architecture. It handles three tasks from a single set of weights: text-to-image generation, instruction-based image editing, and subject-driven personalization, with no switching between separate systems.
That last point matters more than it sounds. Most open-source image pipelines today require you to swap checkpoints depending on whether you want to generate or edit. HiDream-O1 collapses that into one model. The reported consequence: fewer failure modes at the seams between components, more coherent text-image alignment, and a simpler deployment footprint.
The architecture bet that paid off
The core innovation is the Pixel-level Unified Transformer (UiT). At the heart of HiDream-O1-Image is a UiT, a novel architecture that encodes raw pixels, text, and task-specific conditions in a single shared token space. Think of it like an LLM that reasons over images natively, rather than a diffusion model bolted onto a text encoder.
Where almost every recent text-to-image model is a latent diffusion transformer operating on VAE-compressed tokens with text routed through a frozen T5 or CLIP, HiDream-O1 runs the diffusion transformer on raw pixels, with text and task conditions sharing the same token space. This matters because latent compression is lossy: high-frequency visual details get destroyed before the model even starts generating, capping the ceiling on fidelity.


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves