
Computer-use agents , models that look at a screenshot of a screen and autonomously click, type, and navigate GUIs to complete tasks , have mostly lived in the cloud. You send a screenshot up, get an action back, and hope your data doesn't linger somewhere you didn't intend. Holo 3.1, the latest release from Paris-based H Company, is a direct challenge to that model. The whole family is designed to run locally, on hardware you already own, with nothing leaving your network.
What broke in production
Holo 3.1 is a direct response to what broke when teams shipped the previous Holo3 generation: performance in one environment didn't transfer to another, third-party agent frameworks behaved differently, and almost everyone wanted to run the model closer to the workflow instead of in someone else's cloud. The fix isn't a single tweak , it's a full-family release that addresses all three pain points simultaneously.
As teams moved Holo3 from evaluation to production, the same challenge kept surfacing: strong performance in one setting does not necessarily transfer to another. Mobile devices, alternative agent harnesses, and different execution frameworks all introduce their own sources of distribution shift. Holo 3.1 was built specifically to close those gaps.
The model family: 0.8B to 35B
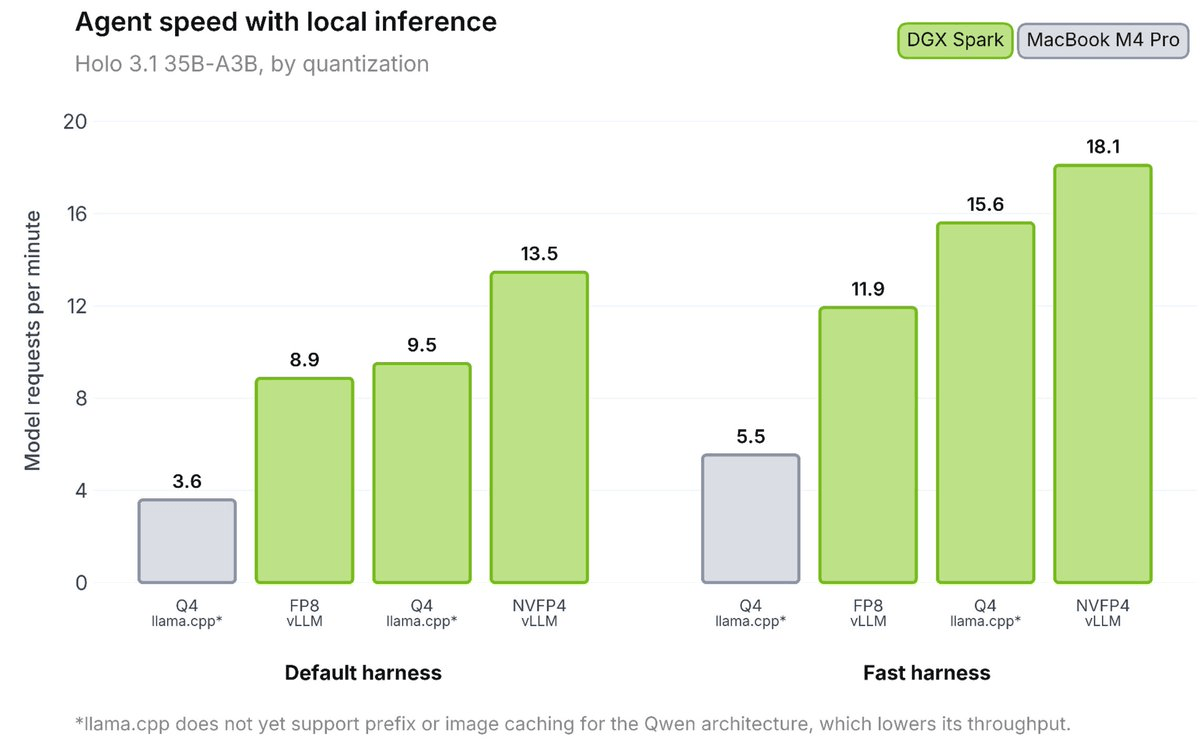
Holo 3.1 is H Company's family of computer-use agent models, built on the Qwen architecture, that operate across web, desktop, and mobile. It ships in four sizes , 0.8B, 4B, 9B, and a 35B-A3B flagship , and, for the first time in the Holo line, quantized FP8, NVFP4, and Q4 GGUF checkpoints so the agent can run fully locally on a Windows or Mac machine, or on a DGX Spark on the same network.
The 35B-A3B naming reflects a mixture-of-experts design: a 35-billion-parameter model with roughly 3B active parameters per token, which is why it can be both the top performer and a realistic target for quantized local inference. Mixture-of-experts (MoE) means only a fraction of the network activates for any given input, making a nominally large model behave much cheaper at inference time. MoE means you get 35B-level accuracy at roughly 3B-level inference cost , which is how a 35B model fits in 12GB VRAM with Q4 quantization.


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves