
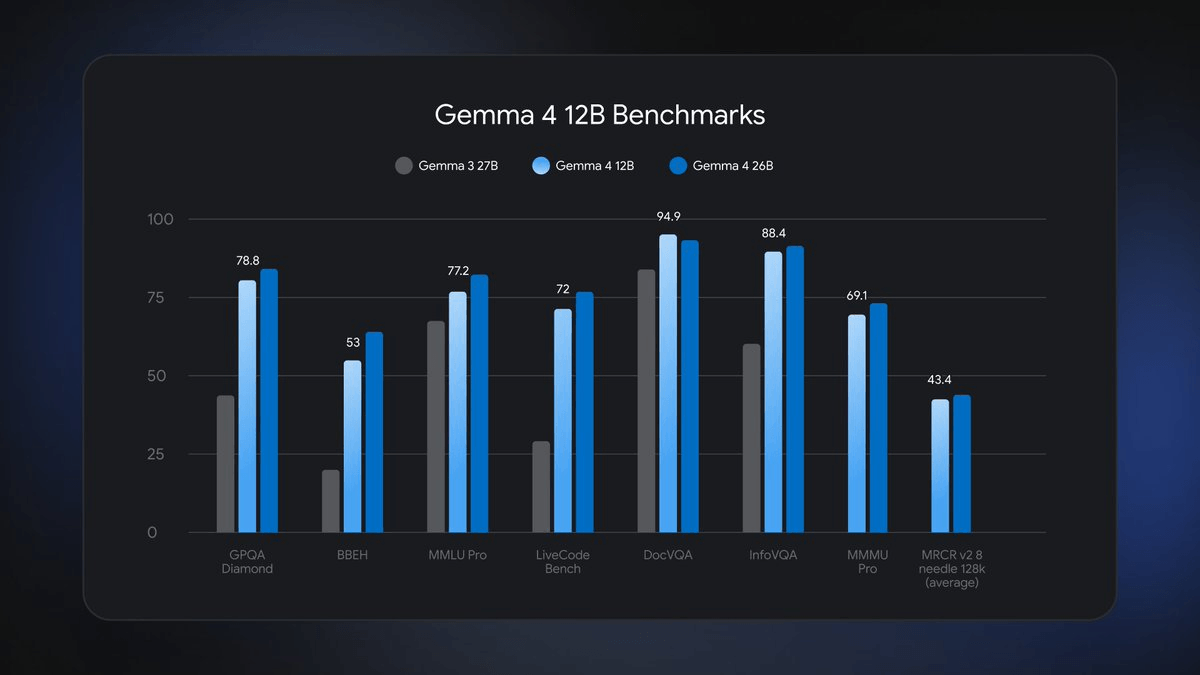
Google DeepMind just dropped Gemma 4 12B, and the headline is deceptively simple: a 12-billion-parameter model that runs on your laptop and handles text, images, audio, and video natively. What's actually interesting is how they pulled it off. The model throws out the multimodal encoder playbook entirely, and the results are hard to ignore.
Gemma 4 12B is designed to bring agentic multimodal intelligence directly to laptops, bridging the gap between the edge-friendly E4B and the more advanced 26B Mixture of Experts model, while also being the first mid-sized model in the Gemma family to feature native audio inputs. It ships right now, free, under an Apache 2.0 license, which allows free use, modification, and commercial deployment -- a change from Gemma 3 and earlier, which used Google's source-available Gemma Terms of Use rather than a fully open-source license.
The architecture bet that changes everything
Most multimodal models work by bolting separate specialist networks onto a language model. You have a vision encoder (think CLIP or a Vision Transformer), sometimes an audio encoder, and the language model sits downstream waiting for their outputs. Previous multimodal models, including earlier Gemma generations, attached a separate vision tower -- a SigLIP-style encoder of roughly 550M parameters -- and an audio encoder onto the language model. Those encoders had to finish processing an image or audio clip before the language model could even begin.
Gemma 4 12B cuts all of that out. Google trained it with an encoder-free architecture to integrate audio and vision input directly. For vision, they replaced Gemma 4's vision encoder with a lightweight embedding module consisting of a single matrix multiplication, positional embedding, and normalizations -- allowing the LLM backbone to take over visual processing. For audio, they eliminated the separate audio encoder entirely, slicing raw 16 kHz audio signals into 40ms frames and projecting them linearly to the LLM input space.


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves