
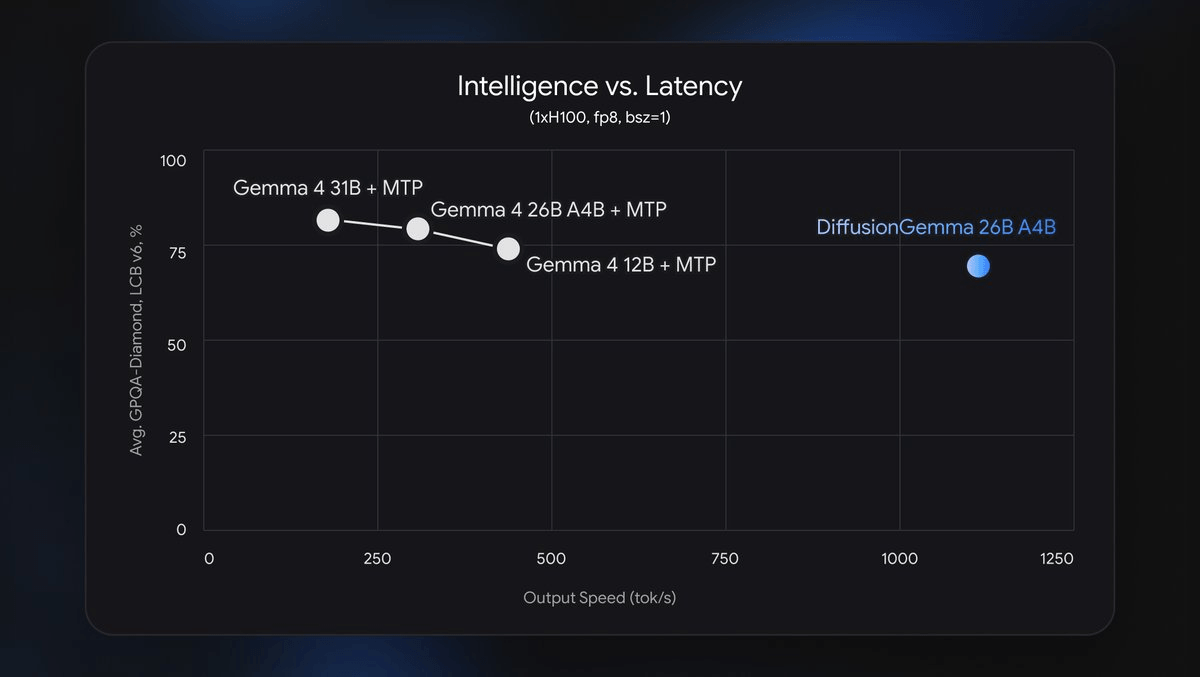
Google DeepMind just released DiffusionGemma, an experimental open-weights model that throws out the fundamental assumption every major LLM has been built on: that text must be generated one token at a time, left to right. Instead, it borrows the core idea from image diffusion -- start with noise, iteratively refine -- and applies it to language. The result is a model that can hit over 1,000 tokens per second on a single H100, a speed tier that no autoregressive model of comparable size can touch on the same hardware.
It's free, Apache 2.0 licensed, available right now on Hugging Face, and it runs on a consumer RTX 4090. But there's a real quality tradeoff, and Google is unusually candid about it.
Why autoregressive models have a speed ceiling
To understand what DiffusionGemma does differently, it helps to understand why standard LLMs are slow in the first place. Autoregressive models -- GPT, Llama, Gemma -- generate text by loading the full set of model weights from GPU memory, predicting one token, then loading the weights again for the next token. At low batch sizes, this process is memory-bandwidth-bound: the GPU spends most of its time loading weights from high-bandwidth memory to compute units, one token at a time. The compute cores sit mostly idle.
Generating 256 tokens autoregressively requires 256 separate forward passes on sequences growing from 1 to 256 positions. DiffusionGemma does the same in as few as 20 forward passes on a 256-position sequence -- a 12x reduction in the number of passes. That's the core of the speed story.
How diffusion actually works for text
Text diffusion borrows from image generation. Instead of predicting the next token, the model starts with a canvas of random placeholder tokens and iteratively refines them all at once. DiffusionGemma generates and refines a 256-token canvas in parallel. By providing the GPU with a large parallel workload, it utilizes tensor cores that would otherwise sit idle during local serving.
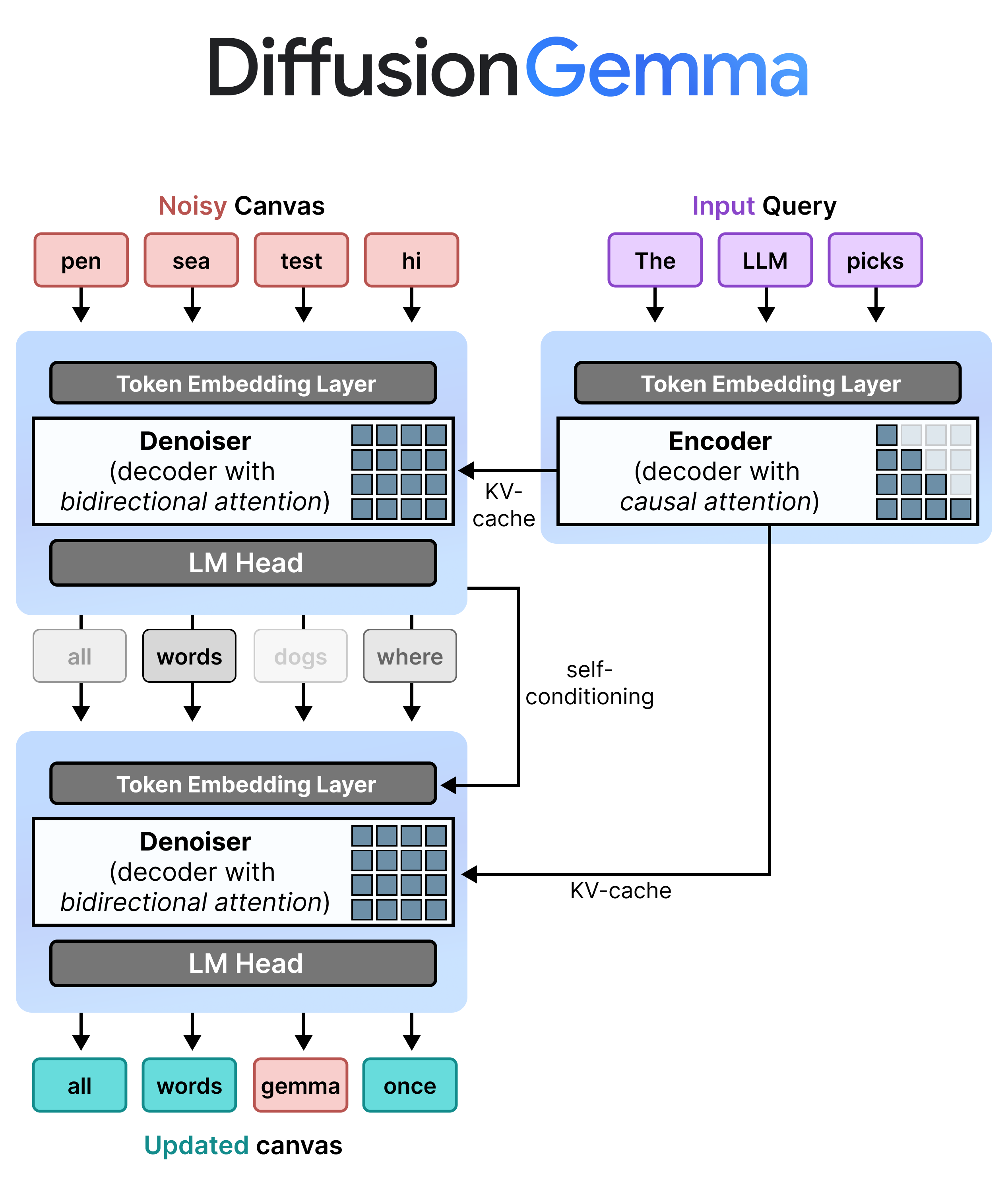
The key architectural innovation is bidirectional attention during the denoising phase. Standard LLMs use causal (one-directional) attention -- each token can only look backward at what came before. DiffusionGemma's denoiser lets every token on the canvas attend to every other token simultaneously. This matters because:


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves