
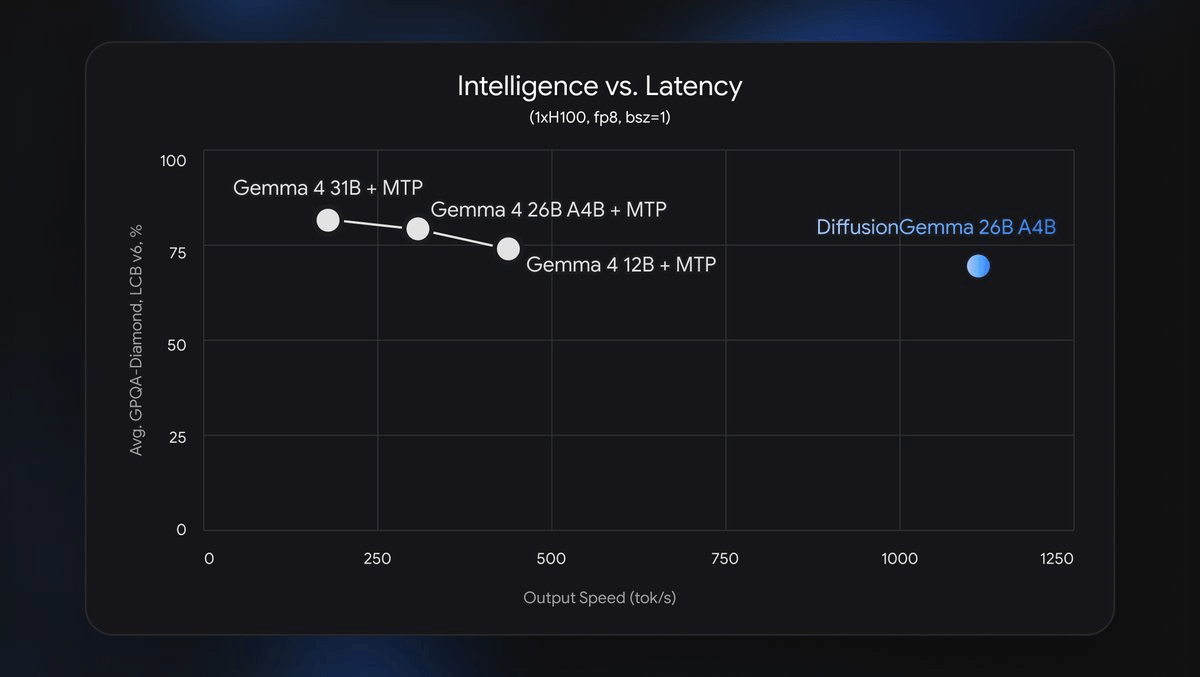
Google DeepMind just shipped something that looks less like a language model and more like an image generator applied to text. DiffusionGemma is a new experimental open-weights model that abandons the token-by-token generation loop entirely, instead denoising entire 256-token blocks in parallel , reaching over 1,000 tokens per second on a single NVIDIA H100 and up to 4x faster output than standard autoregressive models on dedicated GPUs.
This is not a quantization trick or a speculative decoding hack. It is a fundamentally different generation paradigm, and it is now available for free under an Apache 2.0 license on Hugging Face, Kaggle, and Vertex AI.
The problem with the typewriter
Every major language model you have used , GPT, Claude, Llama, Gemma , works the same way under the hood: it predicts one token at a time, left to right, each step waiting for the previous one to finish. Autoregressive models use causal masking so the model can only attend to previous tokens, which is what enforces the left-to-right generation constraint. This works well in cloud deployments where servers batch thousands of user requests together to keep GPUs busy. But locally, for a single user, the primary bottleneck is memory bandwidth , the model must repeatedly load weights from memory to generate text one token at a time. Your GPU's tensor cores sit largely idle, waiting for the next "keystroke."
DiffusionGemma flips this. By shifting the decode bottleneck from memory-bandwidth to raw compute, DiffusionGemma generates up to 4x faster token output, achieving over 1,000 tokens per second on a single NVIDIA H100 GPU. On an H200, the FP8 version reaches 1,008 tokens per second at batch size 1 on a single H100, and 1,288 on H200 , roughly six times a standard autoregressive baseline, according to vLLM benchmark results.
How text diffusion actually works
The mechanism borrows directly from image generation. Think of how Stable Diffusion starts with pure visual noise and progressively refines it into a coherent image through many denoising passes. DiffusionGemma does the same thing, but over discrete text tokens:
- The canvas: The model starts with a 256-token block filled with random placeholder tokens.
- Iterative denoising: Over multiple forward passes, highly confident tokens get locked in and used as context clues to resolve adjacent positions , the whole sequence snaps into focus progressively.


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves