
Getting a language model to run fast on a phone is already hard. Getting it to run fast without retraining it is a different problem entirely. That is exactly what Google Research's new work on frozen Multi-Token Prediction solves, and it is already live on Pixel 9 and 10 devices powering features like AI Notification Summaries and Proofread.
The bottleneck no one talks about
Standard language models generate text autoregressively, meaning they process and output just one word (or token) at a time. This step-by-step process creates a bottleneck, underutilizing the phone's processing power while straining its memory bandwidth, which can ultimately slow down the user experience and drain the battery.
The standard fix for this is speculative decoding -- a technique where a small, fast "drafter" model guesses several tokens ahead, and the main model verifies them all in one parallel pass. If the guesses are right, you get multiple tokens for the cost of one forward pass. Building on prior approaches like the EAGLE framework and Confident Adaptive Language Modeling (CALM), Google designed new architectural components to maximize these efficiency gains specifically for mobile environments.
But traditional speculative decoding has a hidden cost on mobile: running a separate "standalone" drafter model (e.g., 128M parameters) competes for limited RAM. Furthermore, a standalone drafter is "blind" to the main model's rich internal state, predicting next tokens based solely on text history without the semantic context the main model has already computed.
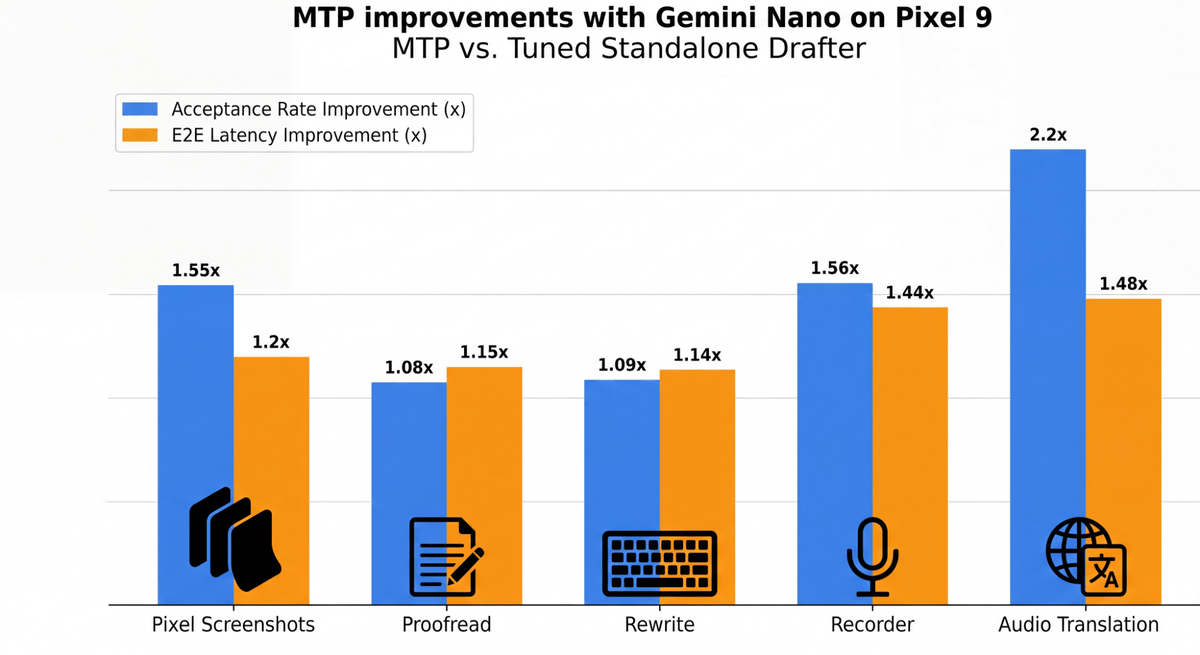
Grafting a head onto a frozen model
MTP addresses these inefficiencies by moving from a standalone architecture to an integrated one. Instead of training a separate small language model to draft tokens, a lightweight Transformer head -- the MTP head -- is appended to the final layers of the main model. This head takes the backbone's final internal representations and uses them to autoregressively predict a sequence of future tokens.


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves