
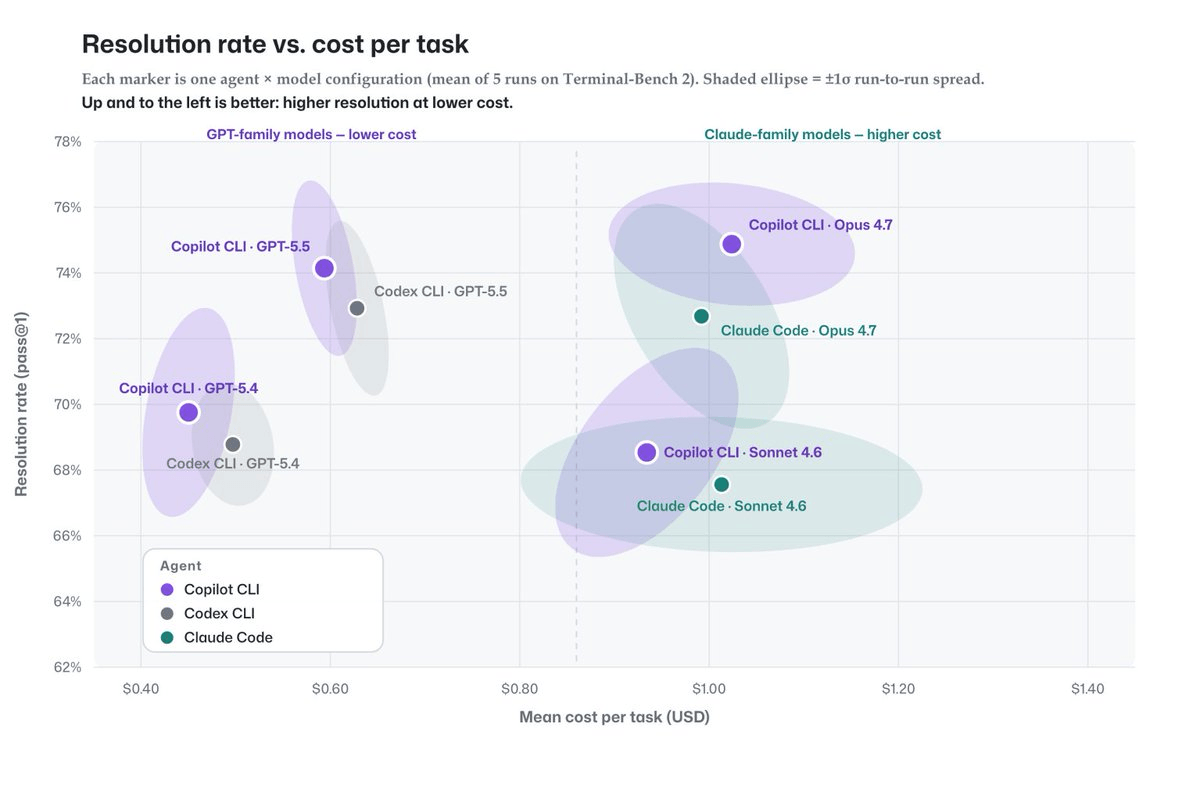
There is a quiet assumption baked into most AI coding benchmarks: the model is what matters. GitHub's latest research challenges that directly. The company has published a detailed benchmark study showing that its agentic harness, the orchestration layer wrapping the model, can match the task resolution rates of model-vendor harnesses like Claude Code and Codex CLI, while consuming fewer tokens across most configurations.
The harness is the product
While the model provides the raw intelligence, the harness shapes how effectively that intelligence is applied. The GitHub Copilot agentic harness is a single shared component of the GitHub Copilot SDK, which powers the GitHub Copilot CLI, GitHub Copilot app, and Copilot code review, along with a wide variety of experiences across GitHub and Microsoft. The key architectural insight here is that improving the harness means every surface benefits, from the CLI to VS Code to Xcode, all at once.
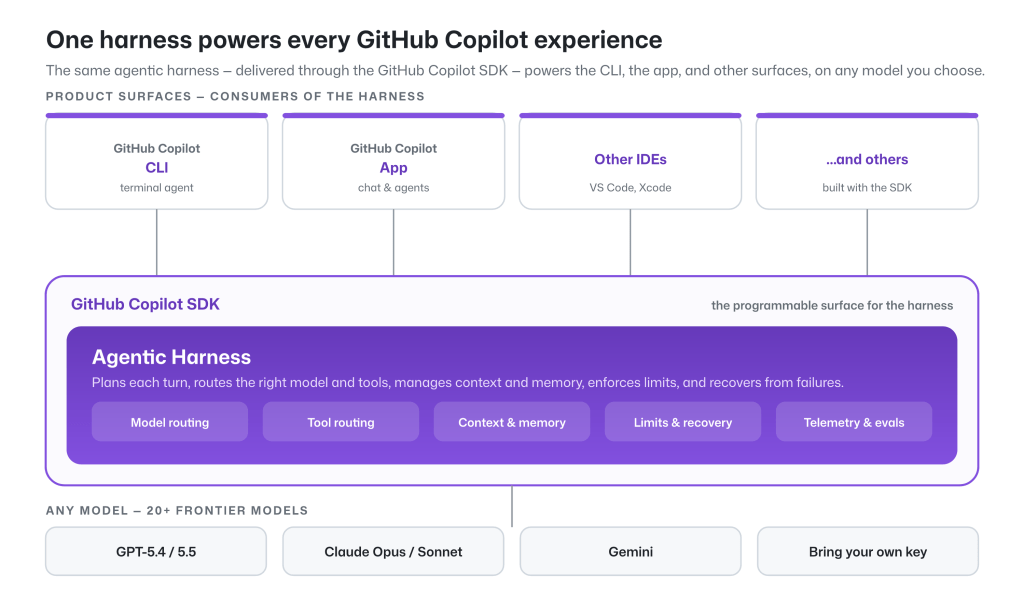
A harness, in this context, is the scaffolding that turns a raw LLM into a coding agent: it assembles context, selects tools, manages the agent loop, handles memory, and feeds results back to the model. Two agents can call the same model and produce very different outcomes because they give the model different tools, different prompts, different memories, and different feedback. That gap is exactly what this study tries to measure.
How the benchmarks were run
GitHub compared the Copilot agentic harness against model-vendor harnesses (Claude Code and Codex CLI) across five benchmarks: SWE-bench Verified, SWE-bench Pro, SkillsBench, TerminalBench, and an internal Win-Hill benchmark, using four models: Claude Sonnet 4.6, Claude Opus 4.7, GPT-5.4, and GPT-5.5.
Here is what each benchmark tests:
- SWE-bench Verified: 500 human-validated bug-fix tasks from real open-source Python repos. The industry standard for coding agents.
- SWE-bench Pro: Harder, multi-step engineering tasks requiring deeper reasoning and broader code changes.
- SkillsBench: Tests how effectively an agent uses and triggers skills to solve tasks.
- TerminalBench: Agent performance on terminal-based, command-line workflows.
- Win-Hill: An internal GitHub benchmark running tasks inside Windows containers, to validate cross-OS generalization.


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves