
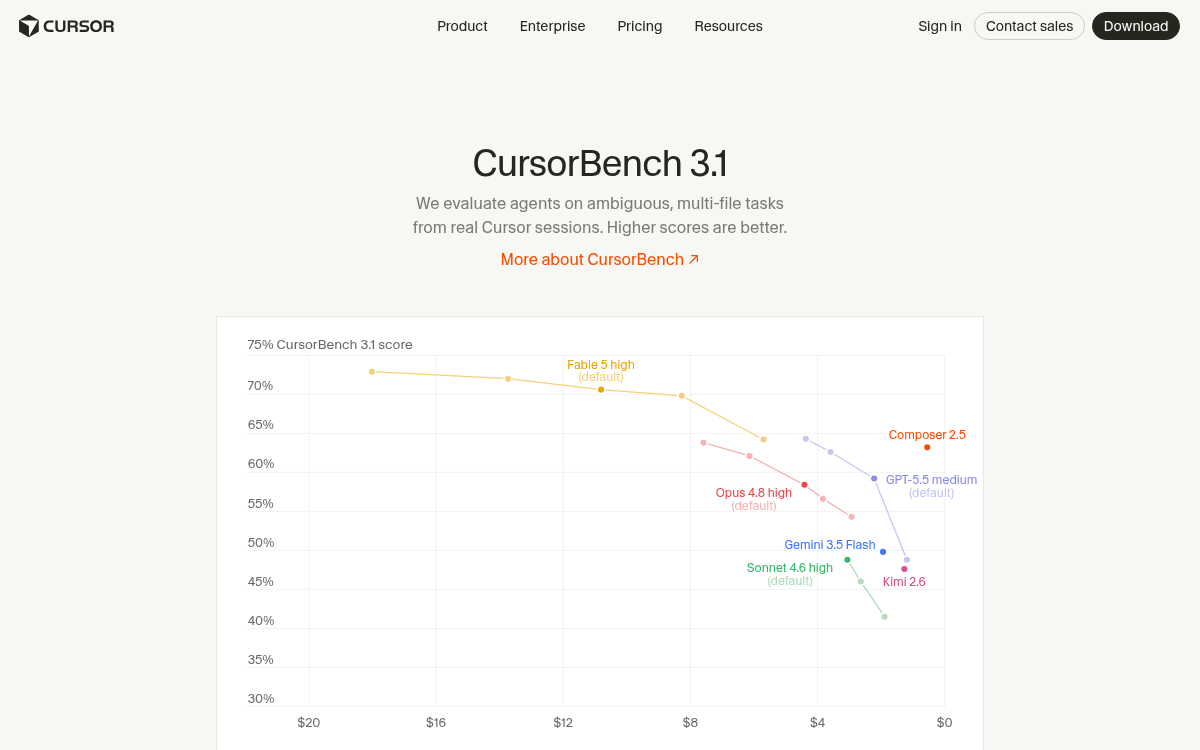
Cursor announced that Claude Fable 5, Anthropic's new Mythos-class model, is now available inside its IDE , and backed the news with a number: 72.9% on CursorBench 3.1, 8 points above the previous best. That gap is not noise. It is the largest single-model jump the leaderboard has recorded, and it comes from a benchmark that Cursor designed specifically to resist the problems that plague public evals.
Why this benchmark actually matters
Most coding benchmarks are built around bug-fixing tasks pulled from public GitHub issues , tasks that frontier models have likely seen in training. CursorBench is different: Cursor evaluates agents on ambiguous, multi-file tasks sourced from real Cursor sessions, which reduces contamination risk and keeps the eval aligned with what developers actually do. The tasks are intentionally underspecified, mirroring how real engineers talk to agents, and graded by an agentic grader rather than a narrow set of expected outputs.
CursorBench produces more separation between models at frontier levels, where public benchmarks are increasingly saturated. That is exactly the context in which Fable 5's 8-point lead is meaningful , it is not a margin squeezed out of a near-saturated benchmark.
What Fable 5 actually is
Claude Fable 5 is Anthropic's first generally available Mythos-class AI model: a new tier above Opus, built for demanding reasoning, long-horizon agentic work, coding, knowledge work, vision, and large-context analysis. The key phrase is "long-horizon" , this is a model designed to hold intent across very long sessions and drive tasks to completion with fewer interruptions, not just answer a single hard question well.


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves