
Cohere's open-source speech recognition model just pulled off a double: after topping the Hugging Face Open ASR Leaderboard for clean audio back in March, Cohere Transcribe has now claimed the #1 spot on the brand-new Far-Field ASR (FFASR) Leaderboard , a benchmark specifically designed to stress-test models in the messy acoustic conditions where enterprise voice AI actually lives.
A benchmark built for the real world
Most ASR benchmarks measure how well a model handles clean, close-microphone audio. That is not how meetings, contact centers, or phone calls sound. Standard ASR benchmarks often miss the conditions that matter most in real-world use: background noise, competing speech, reverberation, distance from the microphone, and other acoustic effects.
Treble Technologies and Hugging Face launched the Far-Field ASR (FFASR) Leaderboard , the first open, community-driven benchmark designed to evaluate ASR models under realistic far-field acoustic conditions. Far-field audio is what you get when the speaker is not right next to the microphone: think a person talking across a conference table, or a customer calling in over a noisy phone line. The benchmark tests models across varying signal-to-noise ratios (SNR , the ratio of the desired speech signal to background noise) and reverberant environments (rooms where sound bounces off walls and creates echo).
The numbers that matter
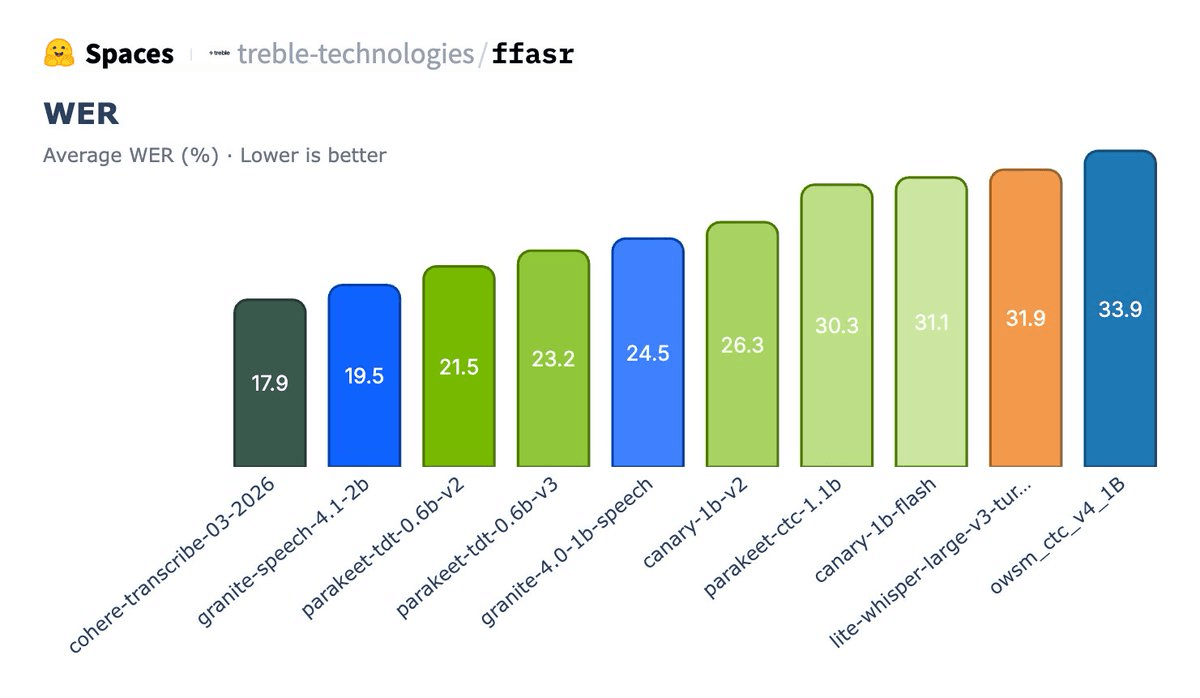
On the FFASR benchmark, Cohere Transcribe achieved a 17.9 WER (Word Error Rate , the percentage of words transcribed incorrectly, lower is better), finishing nearly 2 points ahead of IBM Granite Speech and 3.6 points ahead of NVIDIA's Parakeet. Critically, it ranked #1 across every metric on the leaderboard, not just the average.
This follows its earlier clean-audio win. Transcribe leads the Hugging Face Open ASR Leaderboard with an average word error rate of just 5.42%, outperforming all open- and closed-source dedicated ASR alternatives, including Whisper Large v3, ElevenLabs Scribe v2, and Qwen3-ASR-1.7B. The full leaderboard snapshot at launch looked like this:
| Model | Avg WER | AMI | LibriSpeech Clean |
|---|


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves