
Evaluating voice AI has always been a fragmented exercise: one benchmark tests whether a model knows when to stop talking, another checks if it can count objects from an audio clip, and a third measures whether it can actually resolve a customer's problem end-to-end. Artificial Analysis just collapsed all three into a single number. Their new Speech-to-Speech Index is the first composite metric for native audio models, and the results expose a field that is simultaneously impressive on reasoning and embarrassingly weak on real-world agentic tasks.
What the index actually measures
The index combines three benchmarks, weighted equally, each targeting a distinct capability:
- Speech Reasoning (Big Bench Audio): 1,000 audio questions adapted from Big Bench Hard, covering formal logic, navigation, object counting, and Boolean truth problems. The model hears the question and speaks the answer -- no text intermediary.
- Conversational Dynamics (Full Duplex Bench): Tests whether a model handles the messy mechanics of real conversation -- knowing when not to interrupt during a pause, yielding the floor correctly, responding to mid-sentence interruptions, and continuing to speak when the user says "yeah" or "mm-hmm" (backchannels) rather than treating it as a new turn.
- Agentic Performance (τ-Voice): A benchmark for real-time voice agents on 278 grounded customer-service tasks across retail, airline, and telecom. The model is prompted as a support agent with access to domain tools and a policy document; success means the database ends up in the correct state after the call.
A model must have valid results on all three to appear in the index. That requirement alone filters out many models that have only been tested on one or two dimensions.
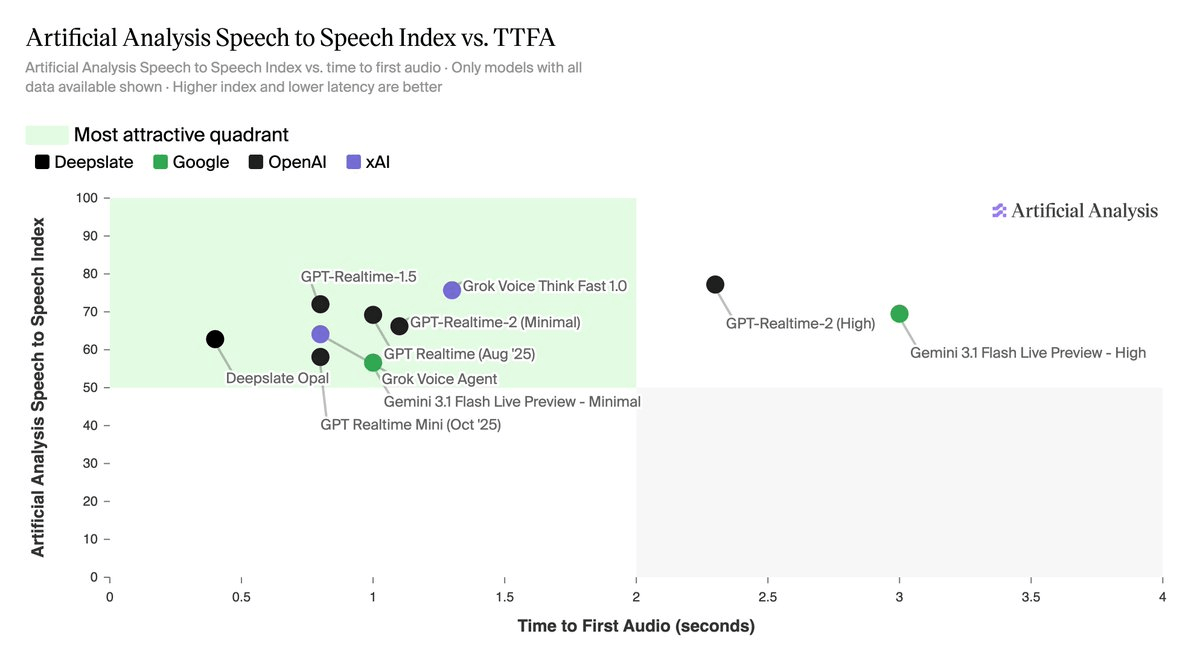
The leaderboard, by the numbers
GPT-Realtime-2 (High) leads the index at 77.2%, followed by Grok Voice Think Fast 1.0 at 75.7%, GPT-Realtime-1.5 at 72.0%, and Gemini 3.1 Flash Live Preview (High) at 69.5%. The gap between first and fourth is only 7.7 points -- tight enough that the choice of model depends heavily on which dimension matters most for your use case.
| Model | Index Score | TTFA (s) | Cost/hr Input |
|---|---|---|---|
| GPT-Realtime-2 (High) |


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves