
As AI models take on more autonomous work , calling tools, chaining decisions, operating as agents , the classifiers that screen what goes in and out of those systems have quietly become one of the most important pieces of infrastructure in any AI product. Yet the benchmarks for evaluating them have barely kept pace. Artificial Analysis, in partnership with NVIDIA, just published the most comprehensive independent guardrail benchmark to date: 20 models, three open datasets, and a combined view of detection quality, latency, and the tradeoff between catching harm and blocking safe content.
What a guardrail model actually does
A guardrail model is a classifier with one job: read a piece of content and decide whether it's safe, and if not, which policy it breaks. It doesn't answer questions or complete tasks , it sits alongside the model that does. Some deployments screen content on both sides of the main model: an input guard catches jailbreak attempts, PII requests, and abuse before they reach the LLM, while an output guard catches harmful responses, data leaks, and toxicity on the way out.
Safety guard models have evolved from simple keyword-based filters to sophisticated LLM-based classifiers. Llama Guard introduced a taxonomy-driven approach using instruction-tuned models for input-output safeguarding. More recently, models from diverse organizations have emerged: Granite Guardian from IBM, Qwen Guard from Alibaba, and ShieldGemma from Google, each with varying safety taxonomies and architectural choices.
The benchmark setup
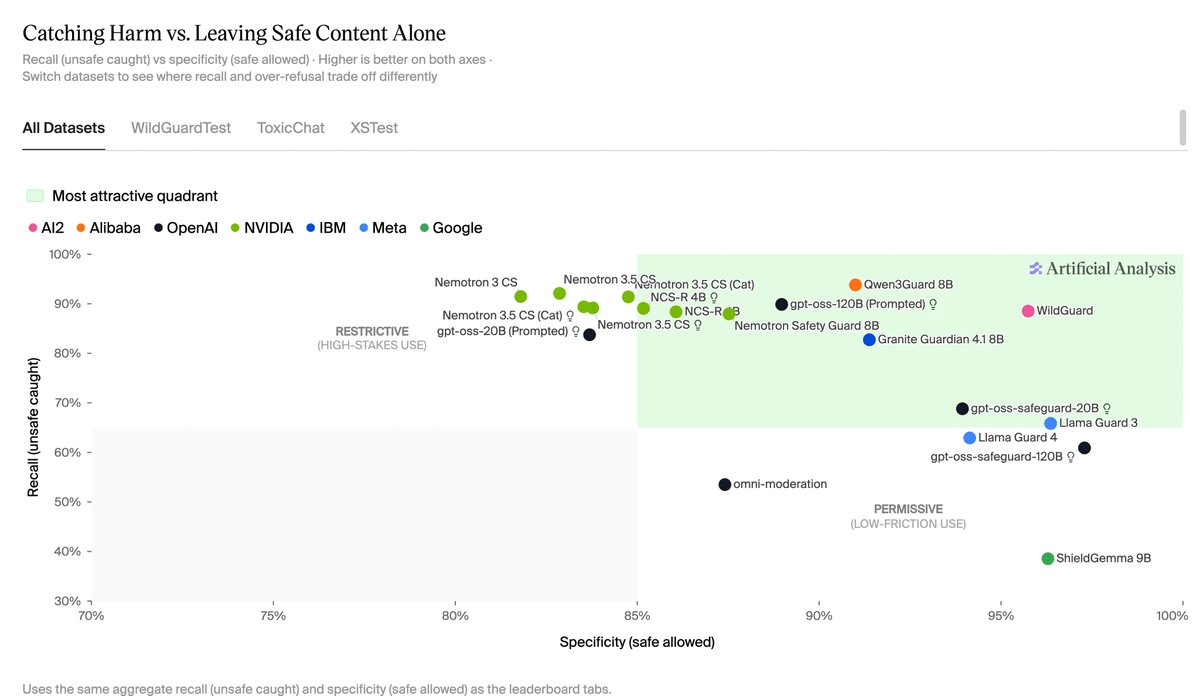
The evaluation ran every model against 7,232 prompts drawn from three open datasets, each testing a different failure mode:
- WildGuardTest (AI2, ~1,700 items): synthetic and human-written prompts labeled for prompt harm, response harm, and refusal.
- ToxicChat (LMSYS, ~5,000 items): real user prompts from the Vicuna chatbot demo, with roughly 7% toxic examples , a realistic distribution.
- XSTest (450 prompts): a hand-crafted contrast set specifically designed to surface over-refusal, with 250 safe prompts that contain words often associated with unsafe requests.
The headline metric is average F1 across the three datasets. F1 combines precision and recall, so a model has to catch unsafe content without creating too many false positives. The comparison includes specialist safety models, model-native moderation APIs, and two general-purpose GPT-OSS models run with an Artificial Analysis-authored classifier prompt as an exploratory baseline. All models except OpenAI's omni-moderation API were self-hosted on B200-class GPUs for fair latency comparison.


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves