
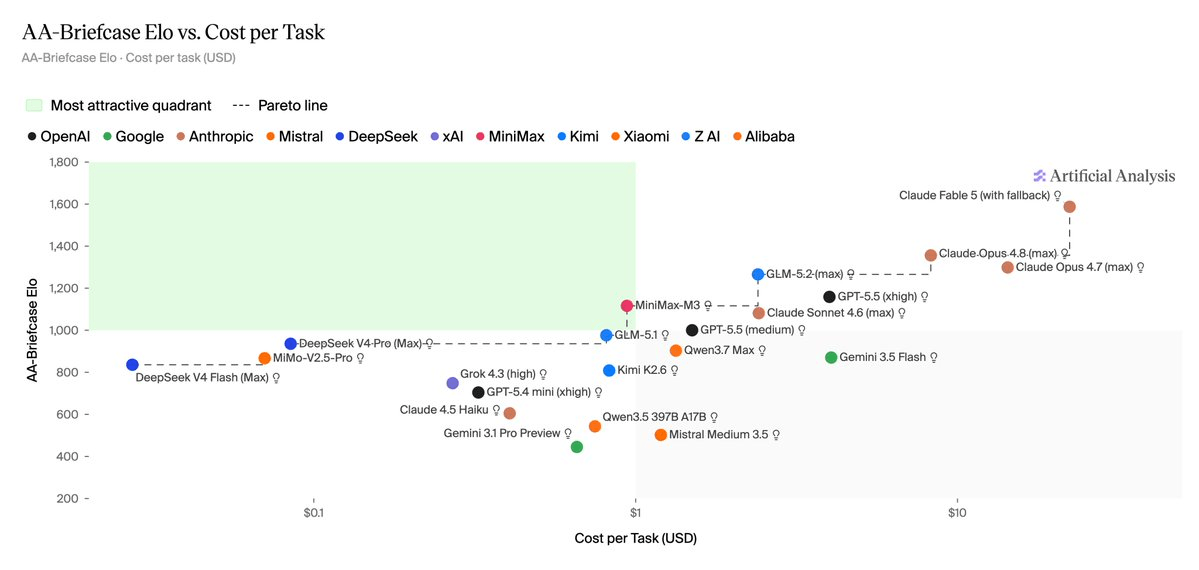
Most AI benchmarks ask a model a question and check the answer. AA-Briefcase asks a model to act like a consultant for several weeks. Artificial Analysis just launched this new agentic benchmark, and the results are both a reality check on where frontier AI actually stands and a strong argument for open-weight models in production deployments.
What it actually tests
AA-Briefcase evaluates models across four multi-week knowledge work projects, comprising thousands of input files and 91 tasks in total. Models must complete realistic professional workflows in fields such as data science, product management, and corporate strategy. These are not toy tasks. The benchmark covers domains like banking operations and heavy industry strategy, with deliverables that include financial models, board presentations, and design mock-ups.
The context each model has to work through is intentionally messy. AA-Briefcase requires models to reason across thousands of inputs, including company documents, meeting transcripts, large-scale data exports, 25,000+ Slack messages and 3,500+ emails. These sources are fragmented, messy, and often contain realistic contradiction, testing whether models can navigate the ambiguity of real-world knowledge work.
The four private scenarios are:
- Data Science -- quantitative work on imperfect datasets turned into business recommendations
- Product Management -- competitive teardowns, PRDs, and go-to-market planning
- Banking Operations -- branch network transformation analysis and financial modeling


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves