
Anthropic has shipped Claude Opus 4.8, an upgrade to its flagship Opus model that arrives at the same price as Opus 4.7 but with meaningful gains across coding, agentic reliability, and safety alignment. The release also bundles a new Dynamic Workflows feature in Claude Code that lets the model orchestrate hundreds of parallel subagents to tackle problems that were previously too large for a single agent pass.
Better numbers, same bill
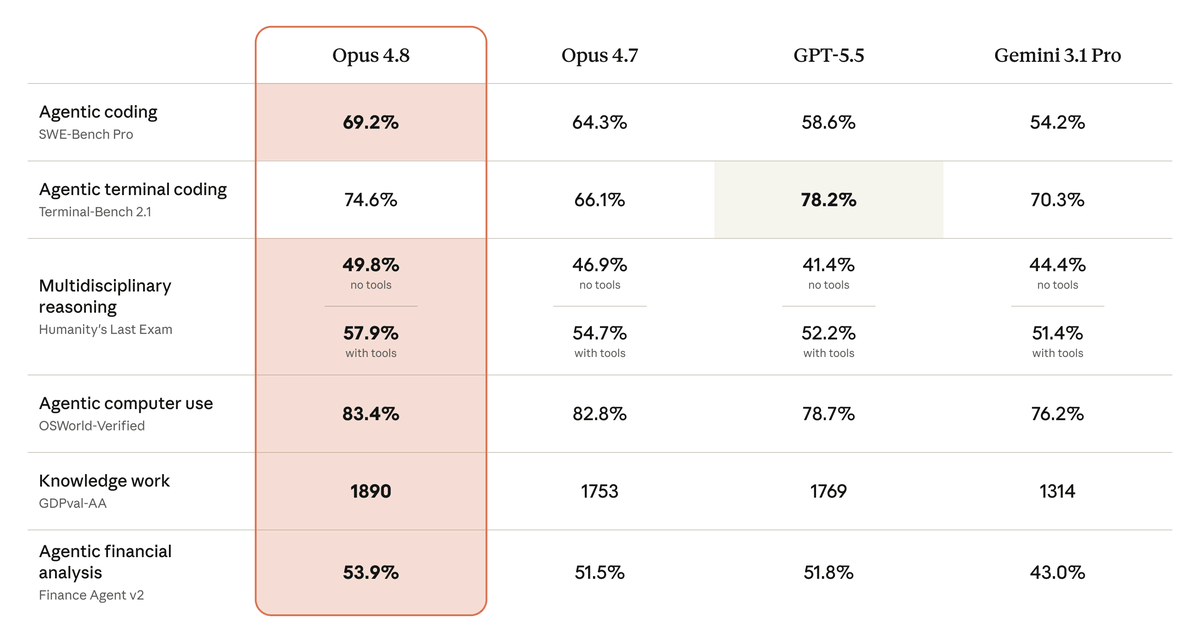
Opus 4.8 is Anthropic's most capable general-access model at release, with improvements across software engineering, agentic tool use, reasoning, computer use, and knowledge-work benchmarks, while shipping at the same price as its predecessor. Pricing for regular usage is $5 per million input tokens and $25 per million output tokens , identical to Opus 4.7.
The real pricing story is in fast mode. Fast mode at 2.5x speed existed on Opus 4.7, but what is new in 4.8 is the price: $10 input / $50 output per million tokens, 3x cheaper than Opus 4.7's fast mode. For latency-sensitive production workloads, that changes the math significantly.
On the benchmark side, on SWE-Bench Pro for agentic coding, Opus 4.8 scored 69.2%, up from 64.3% for Opus 4.7. It scores 84% on Online-Mind2Web for browser agent work, takes the highest recorded score on Sierra's Legal Agent Benchmark as the first model to break 10% on the all-pass standard, and is the only model to complete every case end-to-end on Hebbia's Super-Agent benchmark while matching GPT-5.5 on cost.
There is one honest caveat. Terminal-Bench 2.1 for agentic terminal coding still belongs to GPT-5.5 at 78.2%, with Opus 4.8 coming in at 74.6% , strong, but not first. If your workflow lives entirely in a shell environment and you benchmark by terminal autonomy alone, GPT-5.5 still leads on that single metric.
The real upgrade: honesty and self-correction
The headline benchmark gains are real, but the more interesting improvement is behavioral. Anthropic reports Opus 4.8 is roughly four times less likely than Opus 4.7 to let flaws in its own code pass unremarked. In long-running agentic sessions where the model is writing and executing code autonomously, this compounds quickly , a model that flags its own mistakes early saves far more time than one that silently ships broken output.


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves